Issue # 25 DTACK GROUNDED Newsletter - November 1983

EVEN MORE HARDWARE:
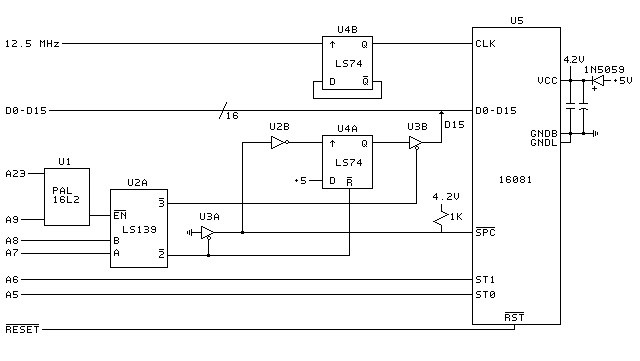
Below (yawn) is a photo of a real, working Nat Semi 16081 math chip peripheral to both the static and dynamic RAM DTACK boards. Hey, didn't we do this last issue? Well, the one below has lots less chips because we know how to interface it this time. In fact, what we have below is the circuit on the back page, except that the PAL memory decode chip has been replaced with two 74LS30s and a 74LS32. We made that change for two reasons: 1) The PAL could decode to any memory location, whereas we only need to decode to one specific memory location, and 2) PALs can hint at secrecy, and we don't want to be secret about our production math chip board, the UBQ-1W, of which the prototype is below.
The UBQ stands for Unbelievably Quick and Dirty, on account of we are going to go ahead and get the damn thing built without worrying about niceties such as additional I/O. We are not only going to be the first to reveal how to interface the 68000/16081 combination,
Page 1, Column 2
we are ALSO going to be the first to SHIP a board- level product! The initial board will be for those who want to learn something about the 16081 or who have an urgent need for high-speed computation. About next summer we will doubtlessly have a nicer board, but the math chip will be mapped into the same memory space as the UBQ-1W, so your software won't have to be changed.
DTACK PASCAL SUPPORT:
We know you aren't going to believe this, but Apple PASCAL v1.1 is supported on the DTACK boards now (p6).
BURN BEFORE READING:
Redlands is about hardware this issue; lots of super- secret information about interfacing the 16081 which Nat Semi COULD give you if they wanted to, but for some reason won't. See pages 24-28. Programming info about the 68000/16081 is on p25 col 2 and an p16 col 2.
DTACK Grande UPDATE:
We have an update on the Grande boards, which are now being routinely shipped (p15). For you newchums, that's our affordable 128K - 1 meg 12.5MHz 68000 board (1 wait state). A vigorous defense of high level languages can be found on p13 col2. Floating point accuracy benchmarks on p12. Rumors on p22 col 2 (what would this newsletter be without a few rumors to monger?), FACTS on p23. Mail call is on p9, 60000 vs Intel architecture on p20 col 2. You wanna copy this copyrighted rag? See p23 col 2. For the usual rantings and ravings, just open the newsletter at random.


Page 2, Column 1
MATH CHIP STUFF:
We neglected to point out that the photo of the prototype QD-1 board an the cover of the last issue included a mirror to show something of the wiring on the bottom of the board, which uses the 3-M prototyping stuff, much superior to wire wrap in our opinion. The mirror arrived directly from Death March Dunkerson's boudoir!
Oh, yes: you will recall that we had plans A, B and C to get that math chip running. Plan A ALMOST worked! Using asynchronous clocks, the peripheral worked 799 times out of 800, on average. This average was the same whether a 6MHz 16081 was tied to an 8MHz or 12.5MHz board, which strongly suggests that it was the asynchronicity, not marginal timing, which caused the hangups.
When we went to plan B and fed the 16081 with a clock that was the 68000's clock, only divided by two, the board worked 100% of the time. So we think we will keep our long-in-the-tooth project engineer around a while longer; every now and then he does something right. We'll keep the youngster around, too: 799 out of 800 ain't bad considering nobody else out there has figured out how to connect the 16081 and the 68000. We will, of course, keep the method a deep, dark secret.
Did you know that those outfits making $35,000 68000- based UNIX machines are all in the process of adopting a $2,500 floating point board from SKYE which they are, naturally, passing on to their customers for $5,000? Did you know that UniSoft, the 68000-UNIX software house, is adopting their UNIX for that high priced board? Did you know that Silicon Valley Software (68000 FORTRAN) is doing the same thing? Did you know that our QD-1 prototype provides essentially the same performance as that $5,000 (retail) circuit board?
TRANSCENDENTAL STUFF:
Several months back at least one reader (we forget who) recommended a "Software Manual for the Elementary Functions," Cody & Waite, Prentis-Hall 1980 (269pp, $22). We ordered the book and dutifully put it in our bookcase alongside the Hart book, "Computer Approximations." After yet another recommendation we finally took the book down and examined it.
Cody & Waite have taken the material in Hart and have filtered it into specific software routines which include flowcharts. Unlike Hart, they provide virtually no choice in algorithms. (They do provide a limited number of different approximation formulas for differing precision.) They did in a more professional manner what we did (or tried to do) in our own explanation of particular transcendental algorithms,
Page 2, Column 2
except that we took the additional step of actually providing source code instead of just flowcharts.
Of course, that source code is specific to the 68000 and would be unsuitable for a general Interest book; we did not intend to imply criticism of Cody & Waite.
While the material in this book is more 'accessible' to engineering types than the material in Hart, it is far from "TRANSCENDENTALS MADE SIMPLE!" (Incidentally, Cody & Waite refer to their book as a 'manual.') For instance, their EXP function algorithm is apparently the one we selected, but we aren't sure because of the unusual (to us) notation used. In their preface they explain:
"Almost the entire text of this manual has been prepared on a computer. While this process his simplified the writing and proofing of our work, it has also introduced limitations on the use of mathematical symbols and notation. Subscripts, for example, had to be inserted by hand and therefore were avoided whenever possible. We apologize for any resulting awkwardness in our presentation."
We reported several issues back that there just wasn't such material between Hart and the sort of listings of BASIC transcendental algorithms that BYTE might have published (and probably did) five years ago. Well, we were wrong. The Cody & Waite manual definitely helps fill that gap. We would also recommend (for Apple types, anyhow) that you buy the Hayden "Double- Precision Floating Point for Applesoft" (#09409, $29.95) package if you are interested in this area.
The Hayden package can not only be used to check the accuracy of other algorithms (it calculates using 21 decimal digit precision, slowly) but their transcendental routines are annotated with REMarks. Then you can read what we wrote in issue #16 & #18 and tell us how many mistakes we made!
[We just realized that we are going to have to write yet another transcendental package using the Nat Semi 16081 & the QD-1! And another print and input routine! (Different format and precision, you know.) Groan!]
OOPS! DEPT:
Please fetch the last issue and change the '16032' in the caption under the photo to '16081.' Then turn the issue over and, in the comments in "THE HOST RESETS THE 68000" pen a 'micro' sign (the one that looks like a drunk M) in 'dly 100+ s.' In the next-to-last paragraph on page 27, 'specialty' was misspelled 'specially' which our word speller naturally was unable to correct. Well, nobody's perfect.
Page 3, Column 1
16 BITS < 8 BITS DEPT:
We had occasion to chat with an Apple Computer employee the other day regarding a matter of mutual interest. We happened to also discuss transportable code and the fact that the additional overhead of transportable code slows computers so drastically. "Yep" he replied, "It really surprises a lot of people to discover that their 16 bit computer runs at 8 bit speeds!"
Isn't that a bit foolish, considering competitive factors, we asked? 'But everybody is using transportable code these days,' he asserted. 'Nobody wants to write their code more than once. You just don't find people using assembly language any more. In our group meetings here at Apple, everyone has that point of view.'
What do your confreres think of 1-2-3's domination of IBM software sales as reported monthly in Softalk, we asked? "Softalk? IBM software is not covered in Softalk!" he rejoined. We are speaking of the IBM, not Apple, edition of Softalk, we mildly pointed out. "I didn't know Softalk has an IBM edition!" he stated.
And there, folks, is why Apple stockholders have cause for concern. This guy is intelligent, highly educated in a technical field and a member of a sizable technical group in Apple Computer. Neither he nor, evidently, his confreres have even heard of Softalk, the IBM edition. Therefore, none of thee are aware that the assembly vs. high level battle is OVER in the IBM world, and that assembly won and won big!
They do not know that 1-2-3, written in assembly language, is currently reaping 39% of all IBM software sales on a unit basis and more than 50% on a dollar basis. They do not know that the game which is outselling all other games by a 4-1 ratio in the IBM marketplace is written in assembly language. They have not noticed that the operating system which is utterly dominant in the 16-bit marketplace (MS-DOS) is written in assembly while UNIX, the C-based darling of the computer press, languishes in the starting gate.
Therefore, he was also unconcerned when we passed on a rumor that Lotus was busily re-writing 1-2-3 for Mackintosh in C, not assembly. "Why not?" he asked. "It's more important to HAVE software. It doesn't matter whether it runs fast!"
This guy obviously has not visualized Mackintosh and the PC sitting side by side in a retail computer outlet, and the salesperson demonstrating 1-2-3 concurrently on the two computers. And he has not visualized the customer immediately and unhesitatingly selecting the PC for purchase because it is MUCH faster.
Page 3, Column 2
The marketplace is perhaps the most effective educator there is, but it is very painful for both companies and individuals to learn from the marketplace. Thoughtful and prudent persons might choose other ways of learning. Such as picking up a few copies of IBM Softalk and looking inside the back cover to see what software is or is not selling. Or has the Apple Computer Co. located a vacuum where the IBM PC does not exist and therefore is not a competitor?
(The guy we were talking to would be astonished to discover that 1-2-3 has 39% of ALL software sales, not just 39% of the spreadsheet or 39% of the business software. Naturally, the rumor about Lotus re-writing 1-2-3 for Mackintosh in C is merely a wild guess, right?)
MONEY TALKS
but people don't always listen. Two of the industry's best success stories are stumbling just a tad. Apple Computer is predicting profits for the quarter ended Sep 30 that are LESS than last year's profits for that same quarter. How much less? Would you believe 70% LESS? That's their prediction. After Mattel predicted a $65 million loss, the final figure was $156 million, including a $167 million loss from consumer electronics. Convergent Technologies has been the biggest success story of the UNIX-class computer guys in the past one or two years, and is mentioned here because it is moving down into the personal computer area with a desktop computer AND a lap computer. Well, Convergent is suddenly finding it necessary to 'tighten ship'.
In the past two months (as this is written) Victor Technologies has gone from 2,900 employees to 1,500. Is that how Victor is going to become the world's fourth largest computer company? Texas Instruments: you remember them? Every financial analyst in the land has offered the opinion that T.I. would be a $200 stock (it is a little over half that now) if only they would cast off that albatross they are wearing around their neck (the 99/4A). Those same analysts point out that T.I. has no business (pun not intended) being in the consumer electronics business. So T.I. jumped right back in and, guess what? Their sales in the past couple of months were - SURPRISE! - less than their own internal projections.
You already know about Mattel, Atari and Osborne and you should have noticed the frenzied price-cutting going on at North Star and Vector. So has the entire marketplace gone away? Heck, no! A couple of companies are making so much money in the personal computer game you'd think they had their own private printing press.
Page 4, Column 1
ComputerWorld has quoted an IBM spokesman as saying their production of PCs in June was greater than the total of the first three months of the year - and they are falling further behind on orders! IBM PC dealers are on allocation, which is what happens when any company cannot produce enough to keep up with the demand. Is there another such company? Yep.
The Commodore 64 and its peripherals are on allocation RIGHT NOW - and this is being written in September! Better buy your Christmas gifts early! Commodore's big problem is that it cannot build enough product to satisfy demand. And unlike the PC, there aren't a bunch of clones out there to pick up the production shortfall. (Boy, are those clones going to be in BIG trouble when IBM catches up with demand! Fortunately for the clones, this is not likely to happen for a while yet.)
To repeat, IBM and Commodore are the only two companies making it and making it BIG in the small computer marketplace. (That's chauvinistic; Sinclair is doing very well in the U.K.) While Apple is predicting that this quarters' profits will be a LOT less than for the same quarter last year, Commodore continues to rack up an unbroken string of record sales and profits and a growth rate that more than doubles the company size each year. And you know what? Commodore gets no respect! Folks like David Bunnel, editor of PC World, sneer at it and assert that it is in big trouble. It IS?
(Some small companies, such as Eagle, are doing well as are some miniscule companies, such as Digital Acoustics.)
ANOTHER MULTIPLE-GUESS QUIZ:
1. The IBM PC has an operating system written in:
A [ ] Assembly B [ ] High-level
2. The IBM PC has a BASIC written in:
A [ ] Assembly B [ ] High-level
3. In the marketplace, the IBM PC is:
A [ ] Successful B [ ] Unsuccessful
4. The CBM 64 has an operating system written in:
A [ ] Assembly B [ ] High-level
5. The CBM 64 has a BASIC written in:
A [ ] Assembly B [ ] High-level
6. In the marketplace, the CBM 64 is:
A [ ] Successful B [ ] Unsuccessful
7. The Fortune 32:16's operating system is written in:
A [ ] Assembly B [ ] High-level
8. The Fortune 32:16's BASIC is written in:
A [ ] Assembly B [ ] High-level
9. In the marketplace, the Fortune 32:16 is:
A [ ] Successful B [ ] UnsuccessfulPage 4, Column 2
10. Mackintosh's operating system will be written in:
A [ ] Assembly B [ ] High-level
11. Mackintosh's BASIC will be written in:
A [ ] Assembly B [ ] High-level
12. In the marketplace, Mackintosh will be:
A [ ] Successful B [ ] UnsuccessfulSend your test papers to Carl Helmers for grading.
(We considered tossing LISA into that pot above but decided it would be unkind. Mackintosh there is still some hope for. What we do not understand is how the "experts" can continue their promotion of operating systems and even the BASIC language written in high- level (usually Pascal or C) when the marketplace is sending very loud and very clear signals to the contrary.
Your FNE can be - and has been - wrong. The "experts" can be - and have been - wrong. But the marketplace is NEVER wrong! If the software designer and the marketing type and the salesman all support an operating system written in, say, Pascal but the customer keeps his money in his pocket, then the software designer and the marketing type and the salesman are WRONG!
We cannot understand why theory (the "experts") seems unrelated to reality (the marketplace). If YOU understand, PLEASE write and explain it to us!
AN AFTERTHOUGHT:
The UNIX REVIEW points with pride (#2 p.36) to the Fortune 32:16 as in example of a highly successful low- end UNIX system. Highly successful? Well, it IS true that Fortune sells over fifty 32:16s a month. Success is relative, hmm?
THE COLOR COMPUTER:
Isolated from the competitive marketplace as Tandy (almost) is, it's hard to judge how they are doing. So when we read that the Color Computer had been upgraded to 64K and that OS-9 and BAS-09 were available (at extra cost) we decided to look into the computer. So we bought the Sep '83 issue of CoCo, the Color Computer magazine. Our initial impression was that we had got hold of an issue of COMPUTE! with 2/3 of its pages missing.
The ads were for games, real keyboards (the Co Co doesn't have a real keyboard), games, cassette holders, more games... CASSETTE HOLDERS? We rapidly looked through the rest of the magazine and re-checked the date of the magazine. Folks, we are coming up hard on the end of 1983 and CoCo magazine has LOTS of ads for CASSETTE HOLDERS! End of interest.
Page 5, Column 1
CRIMINAL ACTIVITIES:
We now have a program called Word Plus, by an outfit called 'Oasis', running on our Eagle II. The last issue was the first we used it on. Anybody notice fewer misspelled words? Naturally, the restrictions on the license state that you can only use this program on one machine. You may remember that we have one Eagle II at home and another at work so we can work on this newsletter, manuals, etc. either place. But we can't use that program on TWO machines, and we really didn't want to buy two copies of the program. What to do?
The solution is obvious. We now carry the work Eagle at home with us at night, and back to work each morning. This way we comply with Eagle's restrictions legally, where if we just carried the floppy disk back and forth it would be illegal... what do you mean you don't believe us? Would we ever lie to you?
By the time you read this, LISA will cost a lot less if you buy it without software ($6995 to be exact). Since the software is already paid for, this makes lots of sense, about as much as Oasis' restrictions as applied to your FNE's particular situation.
LISA's software is 'locked' by a bipolar PROM containing a serial number. If the software on your hard disk (ProFile) does not match the PROM, goodbye software. The PROM with the serial number happens to be the same PROM that Apple uses in its printer interface for the Apple II. If you want to know the serial number of your LISA, you just plug that PROM into an Apple II printer interface and read it out. The next step, blowing a serial number PROM for LISA with whatever serial number you want should not be difficult for any enterprising types out there.
A very special kind of odor is beginning to emanate from a small computer manufacturer which went public recently. No, they are not going broke (not soon, anyhow); in fact they have an embarrassingly large amount of cash due to their public stock offering. This particular odor is the type which focuses the gaze of grand jury foremen (forepersons?) and which raises the hackles on the back of the necks of prosecuting attorneys. The rumors - make that murmurings - have it that many of the SALES in the highly profitable quarter that immediately preceded the public stock placement WEREN'T.
Well, the headline DOES say 'Criminal Activities'!
NIGHTMARISH STUFF:
Shortly after mailing the last newsletter, we had this nightmare which remains very vivid. It seems that we were back on the fifth floor quarters of the Motorola
Page 5, Column 2
sales offices in the city of Orange. The time is a bit vague but it seemed to be over a year in the future. We were attending a technical seminar very like the one we attended regarding the 68000 in Aug '81, only this seminar was on the 68020. For some reason the lecturer, Dr. Mal Hackson, was wearing little horns and a forked tail on this occasion. His talk began conventionally enough:
"The 68020 will be considerably superior to the 68000 or 68010 in performance," Mal stated. "In addition to the obvious advantage of the wider data bus and a directly addressable memory space of 4 gigabytes, the sizable instruction pre-fetch queue will provide astonishing performance gains for short recursive loops. You see, reasonably short loops will find the instructions already in the 68020's queue and not require memory cycles to re-fetch."
"We have made significant improvements in the microcode and have provided superior shift mechanisms (the only real weak point of the 68000168010) and also have provided superior multiply/divide hardware - and 32-bit multiply/divides, too! Oh, yes; the string micro- instructions have been included. It is amazing," Mal mused, "how such time 32-bit computers spend manipulating character data."
"The 68020 will absolutely devastate the VAX 11/780, especially in a couple of months when we get it up to its full rated speed of 16MHz. Accordingly, it is ABSOLUT VERBOTEN to use the 68020 for any lesser purpose. Motorola is establishing a search-and-destroy team to teach anyone using the 68020 for any simple purpose a much-needed lesson!" Mal asserted, idly scratching behind his left ear with the point of his tail.
"This concludes our seminar. Those of you who wish to share in the enormous profits to be reaped will present a certified check to the cashier for $237,995. This is an absolute bargain price for the GIGANTIMACS, a machine without which it will not be possible to develop either 68020 hardware or software.
On the other hand," and here Mal turned and glowered directly at us, "the cheapskates among you will be branded as such by our demons, er, applications engineers and then given a prioritized exit route to the parking lot."
We noticed they had removed one of the windows so there was a direct drop to the parking lot five stories down (and we left our parachute at home, darn it!). And the application engineers had their brands heated to a nice dull red... at that point the alarm went off and rescued us. Silly dream! Motorola wouldn't make the same mistake twice in a row... would it?
Page 6, Column 1
PASCAL:
"Here is 'Inter68'... I would like to ask you to mention it in your next newsletter, preferably by printing sections 1.1 and 1.2 of the User's manual... the price for the disk and manual is $50 (U.S. funds). Send a U.S. Postal Money Order to:"
Ulrich Schmidt An der Junkersmuehle 33/35 5100 Aachen W. Germany
1.1 Features:
Inter68 is a P-code interpreter for the Motorola 68000. It interprets P-code as defined in the Apple Pascal Operating System Reference Manual (version 1.1), and is therefore able to run Apple Pascal with only minor modifications. Please note that Apple FORTRAN is not supported by this release.
Inter68 allows compilation rates of 2000 lines/minute (compared to 300 lines/minute on the Apple). Programs typically execute 12 times faster than on the Apple (without I/O), and 21 times faster if they make heavy use of multidimensional arrays, packed arrays and records, integer multiplication and division, and floating point computations. Even with I/O, a typical speedup of 5 - 6 can be obtained.
Inter68 resides at address $10000 upwards thus giving you as full 60K work space (you cannot use the bottom 4K because they are occupied by the bootstrap ROM [and I/O - FNE]). All system programs greatly benefit from this additional space: programs which up to now required the compiler swapping option to be enabled can now often be compiled without time consuming disk swapping. The editor can now buffer up to 60 blocks (64 blocks if the system swapping option if enabled).
Inter68 employs a primitive memory management scheme. The interpreter itself is roughly 10K long; all RAM above the interpreter can be used as a pseudo disk. When loading a segment from disk, the interpreter stores a copy of the segment in the pseudo disk, so that the next time the segment has to be loaded the disk need not be accessed. This way the Apple Pascal Editor can be completely contained in a 96K DTACK board (but unfortunately not the compiler).
Inter68 uses the BIOS of Apple Pascal to interface with peripherals. A comprehensive set of 27 BIOS commands has been provided. As long as the calling conventions are observed, the user say configure the host interface according to his requirements. Four special BIOS calls (UserRead, UserWrite, UserStatus, Userlnit) have been set up to allow the use of unit numbers 128 to 255.
Page 6, Column 2
Inter68 can interpret code of negative or positive byte sex (Apple Pascal interprets code of negative byte sex only). Programs may contain segments of different byte sex. Byte sex does not affect execution speed,
1.2 Requirements:
Hardware:
Apple II/II+/IIe with at least one disk drive
DTACK 68000 board with at least 76K
Please note: DTACK speaks of 60K and 92K boards to indicate that the bottom 4K cannot be used as RAM. In this manual I will always refer to 64K boards, 96K boards, 224K boards and so on to maintain consistency with the actual addresses needed to access these RAMs.
- Software:
- Apple Pascal 1.1
- Inter68
- User experience:
- Familiarity with the Apple Pascal System (refer to the Apple manuals)
- Familiarity with 6502 assembly language programming if and only if you wish to modify the host interface.
3.1 Why Full Compatibility Cannot Be Preserved:
The 68000 stores words in memory high byte first, i.e. the high byte is at the lower address, whereas the 6502 stores words in memory low byte first, i.e. the lower byte is at the lower address. Byte values, however, are stored in the same order by both processors. We say that the byte sex of data in both systems is different. Data in 68000 memory has positive byte sex, data in 6502 memory has negative byte sex. This brutal fact accounts for almost all incompatibilities between Apple Pascal and 68000 Pascal.
The reason for this is the inability of Inter68 to determine whether or not a 16-bit quantity should be treated as two bytes or as one word. This is due to the fact that Inter68 internally uses positive byte sex, but has to accept (and byte-swap) data of negative byte sex from the host. All data from the host has to pass through a collection of low level I/O routines, called the 'Runtime Support Package' (RSP). The RSP expects a stream of 16-bit values from the host when reading from a blocked device, but it cannot deduce from this stream the meaning of its elements. This loss of context information is irreversible.
Page 7, Column 1
There is a way around this problem: simulate a machine with negative byte sex on the 68000. But then one his to swap bytes each and every time arithmetic is done with two words; the same holds for all address calculations. Moreover, the instruction set of the 68000 does not contain a 'swap byte' instruction (it does have a 'swap word' instruction(4 cycles)) so that we would have to resort to a painfully slow 'rotate word' instruction (22 cycles). Suppose we want to add two words: this would entail an overhead of 66 cycles (44 cycles to swap the operands, 22 cycles to swap the result back to negative byte sex), far more than the actual addition requires.
Therefore, I had to rule out this method, since it would have degraded the 68000 to an 8-bit processor, and then why use it at all? The drawback of keeping arithmetic and address calculations fast and simple is loss of context information. Fortunately, this has only limited effects. All opcodes and almost all operands of the P-machine are byte values, where byte sex is irrelevant. Only the JUMP opcodes have true 16- bit values as operands. In addition, each procedure and segment contains a set of 16-bit pointers which keep the whole code together.
To avoid speed degradation I have implemented all jump opcodes twice: one set for each byte sex. Whenever Inter68 interprets code of a different byte sex, only the addresses in the main P-code jump table are changed to point to the appropriate routines. The overhead for this method is negligible.
How does Inter68 know when the byte sex changes? At various places in the Apple Pascal system there is information about byte sex, but unfortunately Apple Pascal mostly ignores it. Inter68 uses it! One such place is the first block (block 0) of every code file. A code file can contain up to 16 segment, and for all segments the correct byte sex is recorded in this block (this statement is NOT true for Apple Pascal 1.0 which does not generate any byte sex information at all!).
You may be wondering by now why I care about byte sex at all. Doesn't the compiler ALWAYS generate code of negative byte sex? The answer is 'No'. The Apple Pascal compiler is smart enough to detect that it is running on a machine of positive byte sex. Since we want to be able to run the operating system (negative byte sex) AND the code generated under Inter68 (positive byte sex), Inter68 must be able to handle both kinds of code.
How does Inter68 know when it has read block 0 of a code file? Good question! This is one of the places where the context (here: this block is the first of a code file) is lost, since the RSP has to read all kinds of blocks which are indistinguishable from one another.
Page 7, Column 2
Therefore, we have to step in and help Inter68 by providing a special 'standard procedure' ReadCodeFile. A new op code has been devoted for this procedure and the operating system has been patched with this opcode (done by MAKEPASCAL). See section 3.2 for details.
Heuristic considerations such as the one above have to be made in the case of data files too. The format of data files is completely up to the user. There is no way for Inter68 to decide whether the user intended his data file to contain byte or word quantities. Therefore, Inter68 does no special processing with data files. In practice this means that you will have to re-create your binary data files under Inter68 so that word quantities will be in correct byte order.
There are two data files which the system has to maintain. The first one is the disk directory, residing in blocks 2 - 6. We want to be able to read the disk directory under Inter68 as well as Apple Pascal, so Inter68 must byte-swap the word quantities in the disk directory. Inter68 does this in a dirty way: whenever something is UNITREAD or UNITWRITten starting at block two it is assumed to be the disk directory.
SYSTEM PROGRAMMERS WATCH OUT: the directory need not be byte-swapped as the RSP already does it already for you (and for the operating system). This is not true for other blocks an the disk, of course. If you want to disable this 'feature' simply start reading from block 0 or 1.
The other data file that has to be on-line under both systems is SYSTEM.MISCINFO. This file can reside anywhere on the disk, so here the trick with the fixed block number does not work. Again we have to invent a new 'standard procedure' ReadMiscInfo which takes care of byte-swapping. We cannot use our already introduced ReadCodeFile procedure, as the mix of byte and word quantities is different in both cases.
So such for a general overview. Happiness is P-code compatibility...
6. A Look into the Future:
This project grew out of my desire to get a fast Modula-2 up and running. Having briefly considered to write a Modula-2 compiler for the 68000 from scratch I quickly realized that I did not have the resources to complete such a task in a reasonable length of time. However, I am still determined to implement Modula-2 on the 68000, P-code or otherwise.
I do not care much about Softech's UCSD IV.1. On the Apple, it takes more time and more memory than the fine-tuned Apple Pascal. Admittedly, it has many more
Page 8, Column 1
features, and time and space requirements might be less stringent on the 68000. Its P-code, though, is vastly different from the P-code used by Apple Pascal; it is impossible to integrate it in Inter68.
To me, a more challenging and promising expansion would be a 32-bit Pascal. Pointers and integers would be 32 bits long, reals 64 bits. Unfortunately, this cannot be achieved by just modifying the compiler, all system programs will have to be recompiled before they can be used on a 32-bit interpreter.
I welcome any suggestions in these directions, as well as more mundane bug reports. As I have tried to explain in Chapter 3, not every incompatibility can be called a bug, but as this is the first release of Inter68, it is bound to contain some 'classical' bugs.
Finally, I would like to thank two people: Peter Siebert for many good ideas, discussions and disassemblies, and Pete W. Soule for his monitor SSMON/RC which has helped me very such during this project.
(The Inter68 manual is 20 pages long - FNE)
Ulrich, you don't really think we are going to devote any space in this newsletter to publicize (ugh!) PASCAL, do you! - FNE
A little more seriously; we hope most of you readers did not skip over section 3.1 of the Inter68 manual as that is darned good information to have at hand. It bears on more than the simple issue of PASCAL. It will give pause to those folks who want to emulate the 6502 on the 68000 and will also provide an introduction to the article 'Big-Enders vs. Little-Enders' in Aug '83 (IEEE) MICRO magazine (we mentioned this article in the last issue). The article is about byte-sexedness and word-sexedness and how different floating point formats in different machines are stored and about how one designs a general-purpose bus structure (make that NORMALIZES a UNIVERSAL bus structure).
(The following letter was received later.)
"I an relieved to hear that Inter68 has passed your dreaded reviews. Actually, you can ask P.W. Soule about his opinion of my work; I have sent him a copy of Inter68 as a 'thank you' for his monitor.
"About my background: I am an electrical engineer, 27 years old, with master degrees from Aachen University in electrical engineering and from Imperial College, London, in computer science. Currently I am working as a research assistant at Aachen University doing robotics research.
Page 8, Column 2
"I purchased a board in Feb '93 [just before we found out about the export problems - FNE], then waited a few months for Pascal support to surface, but nothing happened. So I decided to do it myself. I started to write a P-code interpreter in June, and I finished the project in late August. [Your 'squatters and howlers' license is hereby revoked, permanently - FNE.] It took me three months, spare time only, and I was pleasantly surprised how easy and enjoyable it is to program the 68000!
"Last week I hooked up a 256K RAM disk to the DTACK board. It took me 43 seconds to compile a 4000 line program! This is equivalent to a compilation rate of 5300 lines/minute! ...incidentally, isn't the U.S. about to introduce the decimal system?" Ulrich S, Aachen W. Germany
Ulrich, in reverse order: the U.S. seems to be dragging its feet over metrification. For example, in Europe the spacing of capacitor leads has been standardized to integer increments of 2.54 millimeters while in the U.S. we continue to use a tenth of an inch as a standard measure. The European system is obviously superior in this case.
Did we ever tell you the 68000 is fast and easy to program? What's this stuff about dreaded reviews? Your FNE is a pussycat!
ELECTRONICS WATCH:
We have just received the 6 Oct '83 issue of Electronics, the McGraw-Hill biweekly magazine. On page 145, Mitch Kapor asserts that Lotus will add communications and wordprocessor features to 1-2-3. You can sure learn a lot if you read Electronics closely! We wonder if those will be GOOD modules, or just something thrown in which will be carried by the companies' reputation...
On page 293, there is exciting software news that all of you will be interested in. The Boston Systems Office will sell you a single-CPU license for a 68000 debug utility for only $13,000 (Thirteen Thousand Dollars). You can order one for your DTACK board at (617) 894-7800. They're in Waltham, not Boston.
We are going to send another software release on that same page to Otherwise Intelligent. As a (prospective) 16032 OEM he will want to find out about the Pascal, PL/1, Fortran and C compilers which are available for just $97,500 plus royalties. (The ill-informed outfit on that same page which is offering a Cobol compiler for only a four-digit price tag is obviously unaware that software for devices which can linearly address over 64K has to have a five-digit price tag. We will not reveal that the uninformed outfit is Wicat.)
Page 9, Column 1
WE GET MAIL:
"Pete Soule revised his DAS hooked Applesoft so that I have a version that works with the old F8 monitor ROM. Sensenig BASIC still requires an Apple II+ (Applesoft in ROM?) but will work with the old ROM installed. You can mention that folks need but ask for the old version and it will be supplied.
"Saw the Saybrook folks at a show in San Antonio. They don't like you. The board was running; it attracted some attention, but not much. Show special (30% off) was $1500 for 12.5MHz (DRAM of course) running 'without wait states.' You have noticed that the p-systen always clears the screen by printing it full of spaces? I suppose that is transportable. They were running a graphics demo (Apple Pascal vs. UCSD 68000) and notably absent were graphics, since the p-system probably doesn't support much of anything as machine specific as graphics, or even a HOME command. Character graphics is what you get.
"Saw the Columbia portable; advise sale of Compaq stock. Saw ads for Sanyo 128K 1-drive software included PC clone for $995 list; advise sale of everybody's stock." Jeff Null, Director DSEX
DIRECTOR?? Jeff, we would suggest that you wait until the Sanyo is available and is proven to work before selling everybody's stock, and even then we would check whether Sanyo was still competitive. Translation: we do not expect to see that Sanyo any time soon in production quantities.
Why don't the Saybrook folks like us? Is it because we have told lies about them? If so, they have never written to complain. Say: you don't suppose they would dislike someone who told the TRUTH about them, do you?
(Stupid FNE hasn't the foggiest idea what an "old F8 monitor" ROM is.)
"...surely there is no limitation on export of unpopulated boards? Do you have plans to produce a hardware refresh version of the Grande? If so, I would much prefer that. Software refresh contains the seeds of such horrible problems.
"...I noticed a dozen 92K 12.5MHz boards advertised for sale in the unclassifieds in the back of Sept CALL A.P.P.L.E. I hope these are legit - do you know of them?" Ken O Faulconbridge Australia
Ken, in reverse order: that was really just one board. "12 avail" meant "12.5MHz available." You see, the board was a "TEMP-8" which had not been upgraded to 12.5MHz. And that meant the ad exaggerated the price they had paid for the board, since 92K TEMP-8s went for
Page 9, Column 2
$998 back when we were selling them. Incidentally, that board was purchased by someone here in Southern Calif. and arrived via UPS yesterday for an upgrade to 12.5MHz and for documentation. Seems the original documentation got lost.
Hardware refresh is not a magic panacea, especially with the 68000. The 68000 is almost totally bus- bandwidth limited and you simply ain't hardly ever going to get the needed five consecutive clock cycles for a refresh, and the hardware will NEVER know when five FUTURE cycles will be available so as to start an invisible refresh. LISA and the Apple II both whip this problem by appending a refresh cycle onto EVERY memory cycle by time-sharing memory with the video circuitry. Trouble is, that gives LISA an effective 4.8MHz speed while the Grande has, by our preliminary measurements, a 10.5MHz effective speed. And the Apple II could otherwise run at 2MHz.
A nearly bare board (passive parts only) is still a peripheral and the $500 (total) limit still applies. Don't get mad at us, we don't make those rules! In addition, selling partly built boards for pennies of profit while still being responsible for the warranty does not make business sense. As we told someone in W. Germany recently. Sorry!
Did you know that you are the SECOND person from Faulconbridge, Australia to approach us in this regard and also to draw vague hints about export limitations and photocopy machines? (An aside to our other readers: there are now THREE persons from Faulconbridge who correspond with us. One of them has a board and a second MAY have a board soon - $495 without the 68000.) We reply to you as we have the other guy and also a West German: we have absolutely no interest in suing anyone unless we can do so profitably. From many thousands of miles away and across national boundaries that ain't likely to happen. And yes, the damn export regulations frustrate us as much as they do you.
"Dear FNE (Whazzit mean?):" Maurice S Houston TX
FNE started out as Faithful Newsletter Editor. Faithful on account of over 500 pages, most of thee compressed, in print. A while back we decided to give FNE some additional embodyment and assigned him the name Felgercarb Naysayer Eloi. Felgercarb is from the TV space opera 'Battleship Galactica' where it was used as a substitute for an Anglo-Saxon word which means 'not in accordance with the facts.' Naysayer was adopted in tribute to a devastating editorial by Girish Khatre, editor of Electronic Engineering Times. Eloi is from the H.G. Wells science-fiction story "The Time Traveller." As we explained a few issues back, we adopted that fictional surname in recognition of the
Page 10, Column 1
fact that, although we personally prefer static RAM, we realize that dynamic RAM is going to win.
And we use FNE rather than our real name partly to take the sting out of opinions expressed here which may be contrary to YOUR opinions, and partly in recognition that the devices which we write about are such more important than the person who does the writing.
(The following is from a letter dated 1 Aug '83 which we lost under a stack of paper on our desk at home. Bruce is with Micro Technology Unlimited, which makes a 68000 processor board for their own 6502-based personal computer.)
"We are currently evaluating some of our options for languages on the 68000. Frankly our options don't look so hot, as far as getting commercial products ported over to our system. It looks like all the software vendors are still suffering from the familiar if-it- doesn't-cost-over-four-digits-it-can't-run-on-a-68000 syndrome, and are only interested in the 90 UNIX implementations crowd.
"Another alternative we are mulling over is for me to write a BASIC compiler or a small-C compiler for the 68000. If we do the C compiler it will probably be based on Ran Cain's Small C but would be enhanced to include floating point and compile native 68000 object code.
"I don't want to discourage you about HALGOL, but based an my own experiences and comparing them with discussions you've had in the newsletter, I think you have a very, very long way to go before you'll have an operational language. Designing a language is a great deal of fun and a terrific learning experience, but is also full of 'gotchas' to be discovered along the way. That sounds patronizing, and I don't mean it to be. I just have been down similar roads and have been amazed how long it is from the time you think you can see the end of the road until you actually get there, via many hidden detours.
"I'd like to cautiously join the ranks of those who don't think that a 68K attached processor for the Commodore 64 is ridiculous... The disk on the 64 is a joke, however. Flat out it will transfer 300 bytes per second, can only handle 3 open files at a time, and cannot append an existing file... Is CP/M an acronym for CessPool Machine?" Bruce C Raleigh NC
Bruce, it is lucky for you that Digital Research has too many problems right now to send a 'hit man' all the way across the country to Raleigh. Regarding HALGOL: we agree with your comments, but want to point out that we have a programmer who can work 100% of the time on
Page 10, Column 2
HALGOL and does, and that we are almost to the point of getting a preliminary system to work, the disk being the hangup. We are stuck between a desire to implement BLUE SKY ONE ourselves (so we can give away the source code) and the very practical and very slow RWTS in DOS 3.3. This decision is made more complex by the fact that Apple Computer has a new disk operating system which is about to be introduced as standard equipment with the IIe and which will have the kind of speed we'd like, while remaining compatible with (then) standard Apple disks. BLUE SKY ONE would likely be incompatible with DOS 3.3. We know that BLUE SKY ONE is possible because several persons have implemented it. Oh, yes: BLUE SKY ONE plus a two-disk-drive Apple system will load 286K in 20 seconds, so we are not really concerned about the size of the HALGOL run-time package.
So far HALGOL has about 14K object code developed and mostly debugged. We really are making progress. Unfortunately there are things like math processors that pop up and rob time (but are too much fun to ignore). We'll send you the name and phone number of a Princeton graduate student who has already implemented Ron Cain's small C on a DTACK system (but without floating point for now). This guy tells us he hasn't even SEEN Brooke Shields, who is a freshman at Princeton this fall!
While your comments on four-digit 68000 software prices are dead on, for a reason we explained in the last issue, we point with (hopefully understandable) pride to the cross-assembler, Chess program, FORTH, Apple/DTACK operating system and even PASCAL support that DTACK has attracted - all with two-digit prices! And there is more support on the way, although we cannot guarantee a two-digit price tag. For instance: 68000 native code FORTH, p-code Apple FORTRAN, a native code FORTRAN, PHASE ZERO's BASIC and their resident assembler... oh, yes: Chet S's compiled BASIC and Pete S's very good disassembler/monitor, each of which come with a zero-digit price tag. (The media will cost you a single digit.)
(We have just decided that paragraph above might look good in a full-page ad in a national magazine or three.)
"At long last we have begun work on writing the BIOS handler to mate the P4 system to the Apple/DTACK combination... Actually I don't think we have a major disagreement about the relative virtues of assembly language programming, versus the 'slow' P system. However, since we are not in the business of producing commercial software, the transportability of code is in fact a major consideration in our allocation of scant manpower resources. In addition, we have the phenomenon that several of our faculty find it distressing to work on assembler and absolutely refuse
Page 11, Column 1
to do so... Our current plans are to bring up the P4 system and, as soon as you manage to get the Nat Semi math chip into a real live product, modify the system to support the math chip.
"I do believe you have a point in considering the commercial realm versus the academic realm as far as selection of languages. If I were writing software that was speed dependent for commercial release, I undoubtedly would move to assembler... So from one 'Pascal Pusher' to the FNE let se say that I appreciate the speed of assembler. However, we will continue to use Pascal with our 68000 DTACK card to make it more palatable." Tom L
[The following is from another letter received later.]
"Thanks for sending the info on Inter68. The price is certainly low and will be interesting to test. Accordingly, we are buying a copy and I will write you a review after using it for awhile. It would be of interest to several of the folks at the University of Washington.
"We will still play with the PIV.12 system and eventually will send you an 'official report' comparing the PIV and Inter68 approaches. Should be interesting. We also ordered the MINOS from PHASE ZERO. It is nice seeing even more goodies coming out for the DTACK system." Tom L Seattle WA
It sure is nice, Tom! There is lots more elsewhere in this issue on Inter68 - FNE.
(The following correspondence was real but is slightly fictionalized here.)
"I am thoroughly enjoying your 68000 board which I received from you last year, I would like to purchase a Stuffer board, and so enclose $110, I authorize you to ship it to me with shipping charges and customs collect." Hans A Valhall W. Germany.
Dear Mr. Achtung: We sincerely regret that export restrictions forbid us to sell you a Stuffer board since you have already exceeded the $500 limit which we can legally ship to you. However, there must be many other residents of Valhall who would be interested in our products. We are regretfully returning your check! signed FNE
(Later) Dear Mr. Achtung: We are returning that SAME check - again - since it still has YOUR name on it. Also, our government authorities might suspect that someone with your last name and an address next door to yours might constitute sales to the same person. signed FNE
Page 11, Column 2
(Even later yet) Dear Mr. Haack: I am regretfully returning your check, as you have indicated in your letter that you are purchasing the Stuffer board for use by Hans Achtung. You see, on the customs declaration which we must fill out, there is a space for the final consignee as well as for the purchaser. Mr. Achtung has already reached the export limit and cannot legally, from the U.S. viewpoint, be a final consignee. Sorry! signed FNE
(And finally) Dear Ms. Krupp: We are pleased to receive your order in the amount of $110 (U.S. funds) for a Stuffer board, which will be shipped this afternoon, shipping and customs charges collect. We are also pleased that we now have TWO customers in Valhall. We hope you enjoy the use of your board. signed FNE
(Ms. Krupp will doubtless be interested to know that she can also purchase our upcoming math processor board as she is $390 short of reaching her legal limit, and the UQD-1 will cost a lot less than $390 - but without the 16081 math chip itself, which is not yet available across the counter.)
"Well, what's the story? Are you going to make a nice simple 68000 plug-in card for the Apple II or not? I've purchased several books on the 68000 microprocessor and now realize what I'm missing. There are undoubtedly several other persons out there too lazy to write to a nice guy like you [choke! - FNE] to tell you what they want.
"I want 64K of DRAM, DMA, a completed HALGOL compiler and monitor for this card. I want to program in 68000 machine language only, not a combination of 6502 and 68000. I also want a card for a fast numeric coprocessor and a high-res board with dedicated RAM and graphics processor.
"I think you would be wasting your time on a multiple processor board or a multiple numeric processor board. Are you trying to create a CRAY-I? Maybe we can call it the 'FNE-1', 'Cray or Bust' or something even flashier. All this waiting around is enough to make a guy want to switch to an 8088 card. They are available off the shelf, have software, DMA, cost under $400, and they can run rings around the 6502." Chuck M, APO NY
Chuck, believe us, we want a completed HALGOL compiler ourselves! You really do not want to have a Nat Semi 16081 on another Apple board and filter communications through the 1 byte per microsecond Apple bus. Number Nine makes a under-the-hood HIRES board using the 7220. You program in machine language and are interested in an 0088? Your 'FNE-1' suggestion is summarily rejected; we would never name a product after ourself.
Page 12, Column 1
The benchmark listing below is from Terry Peterson. It is a re-write of the benchmark program listed in Dr. Dobb's Journal Sep '83 p.122. The Dr. Dobb's code has two problems: first, it calculates the AVERAGE error. Consider:
2 + 2 = 3 Error = -1
4 + 3 = 8 Error = +1
---
Average Error = 0 (!)Next, an error with a = 2500 is given 2500 times the weight of the same relative error when a = 1. The benchmark algorithm below corrects both of these problems and correctly calculates the R.M.S. (root mean square) relative error.
On page 121 Dr. Dobbs prints some results which are utterly HORRENDOUS! Even though positive and negative errors cancel, there are some HUGE errors reported on that page. It is particularly distressing to note that PL/1-86 with the 8087 math processor had a LARGE error while the 8232 (Intel's 9511A) proved far more accurate than the 8087. But PL/1-86 and PL/1-80 both had ABSURDLY large errors when running with their standard floating point libraries.
For the record, here are some results using Dr. Dobb's ORIGINAL algorithm.
Language Version Result Time
PL/1-86 with 8087 1.01 2477.244 3.7s
8080 Asm'blr w/ 8232 RMAC 2499.995 10.2s
BASIC-86 interpreter 5.20 2179.850 92.2s
PL/1-86 1.01 1641.758 179.6s
Petspeed (normal) 2.6 2500.00009 515.4s
Petspeed w/68000 2.6 2500.00352 22.9s
Applesoft (normal) II+ 2500.00088 477.5s
Applesoft w/DTACK hooks 2500.00352 34.6s
Tasc w/DTACK hooks 2500.00352 20.3s
CBASIC2/Eagle II 2485.763 2640.0sPage 12, Column 2
The first four benchmarks above are reprinted from Dr Dobbs, the two Petspeed benchmarks were taken by Terry and we took the last three. Dr Dobbs did list one 8232 package that wound up with a final result of 2500 even. Petspeed is to Commodore what Tasc is to Apple (a 6502 BASIC compiler). Please note that our Applesoft compatible F.P. package proved much faster but apparently less accurate than the Microsoft 6502 F.P. package. We say apparently, because the Dr Dobbs algorithm allows positive and negative errors to cancel. The run time of CBAS2/Eagle II was 44 minutes!
One might draw the conclusion that nobody knows how to program the Intel microprocessors in floating point. On the other hand, it is a good thing these days to be innovative and those Intel micros are certainly providing innovative answers! Intel does not get credit for the 8232 results; that chip was designed by AMD (the 9511A).
TIME & ACCURACY BENCHMARK 9/16/83
100 REM time and general accuracy test program
110 REM integer i (if needed)
120 iloop = 2500: PRINT "calculating: sum(b*b), b=I(a)/a-1, a=1,2500."
125 PRINT " Where I(a)=tan(atn(exp(log(sqr(a*a)))))."
130 t0 = ti: REM Commodore specific timing variable
140 FOR a = 1 TO iloop
150 b = TAN(ATN(EXP(LOG(SQR(a * a))))) / a - 1
155 z = z + b * b
160 NEXT a
170 PRINT "R.M.S. error = "; SQR(z / iloop)
180 REM next line Commodore specific; others use stop watch
190 PRINT "Time = "; (ti - t0) / 60; " seconds"
200 ENDNow for some results using Terry's revised algorithm, which normalizes errors and does not permit positive and negative errors to cancel:
Language Version Rel RMS Err Time
CBM BASIC 4.0 2.38E-7 552.0s
Petspeed (normal) 2.6 2.38E-7 533.0s
Petspeed w/DTACK 1.27E-9 31.8s
IBM PC/BASICA 1.10 6.83E-5 205.0s
Applesoft II+ 2.38E-7 488.1s
Applesoft w/DTACK 1.29E-9 34.6s
Tasc w/DTACK 1.29E-9 24.5s
CBASIC2/Eagle II 4.56E-6 2740.0sTerry reported the first four results and we did the last four ourselves (plural; our resident full-time HALGOL programmer helped out). If you buy an Eagle II, do so for its word processor, not CBASIC.
The IBM PC is worst, nearly an order of magnitude worse than CBASIC2 which uses the same size F.P. package,
Page 13, Column 1
very slowly. The Microsoft F.P. package, whether run on a CBM or an Apple, is more than an order of magnitude better than CBASIC2 and more than two orders of magnitude better than the IBM. The surprise is the Microsoft compatible DTACK floating point package, which proves to be over two orders of magnitude more accurate than the Microsoft 6502 package even though both use the same floating point number representation (and the same number of mantissa bits, of course).
The only explanation we can offer is that we made no effort to copy all of the Microsoft transcendental routines, other than the logarithm. Instead, we followed Hart (Computer Approximations) and 'rolled our own'.
The DTACK package proved 52,946 times more accurate than the IBM PC with BASICA even though only a 256-1 difference can be attributed to the slightly larger mantissa (32 bits vs. 24). Looking at it another way, the IBM has errors at least 206 times larger than necessary. On the other hand, the DTACK package appears to have made optimum utilization of those 32 mantissa bits since a part in ten to the 9th is about the limit of resolution for one least bit. Please understand that we are not bragging; it would be bragging ONLY if we told you who wrote that DTACK package, which we have not done, have we?
Our thanks again to Terry Peterson of El Cerrito, CA who brought the Dr Dobbs article to our attention and who provided many of the timings published here. Oh, yes: thanks go to Ray Duncan and Dr. Dobbs for getting things rolling.
SPECULATION:
One might suppose that Microsoft somewhere along the line er, fouled up a transcendental algorithm? Like back when Altair BASIC was delivered? And that the folks in the Intel camp have been faithfully copying Microsoft's algorithms ever since? Both the PC and Microsoft's 6502 BASIC have an RMS error of about 200 times one least significant mantissa bit.
If the bad algorithm involves range reduction, that could account for the 8087 providing such bad results because the 8087 does NOT perform complete transcendental functions, just the partials after range reduction. (If you don't know what range reduction is but WANT to know, read our explanation of our transcendental functions in issues 116 and #18.) It's hard to believe that Intel would have gone into production with a bad hard-wired algorithm, and in fact we DON'T believe it. If we wuz gonna suspect one of Microsoft's algorithms, we would first take a hard look at the ATN function. That one gave US fits!
Page 13, Column 2
"Writing code, even system code, in a High Level Language does indeed have a firm rationale. In practice the objective is to use the HLL to get the program running correctly with a minimum of effort and the benefit of all those nice HLL tools. Once the program is running (slowly) and debugged, it is (or should be) analyzed to see where the bottle-necks are and these sections are re-coded in assembler and linked into the code the HLL produced, thus speeding up the program.
"The basis for this is the assumption that '90% of the time is spent running 10% of the code.' Of course this analysis/recode cycle can go recursive and wind up with something that should have been done in assembler in the first place. Quite a few examples can be found in Apple programs that BLOAD in machine code to do the slow stuff - Ampersort for example.
"I realize that many people professing the superiority of HLLs maintain that it should be every byte HLL, but in the real world there is almost always some form of HLL/assembler mix in any application that has to run fast.
"The main driving force behind HLL code is not really transportability, it is maintainability. There are hundreds of starving computer science graduates out on the street that you can hire cheap to fix your HLL code when it breaks. If it were all done in assembler, not only would you have to teach those people assembler but also how the system works, how to run the linker, etc, etc. By having a lot of the code in HLL you reduce the scope of any particular problem and therefore the amount of time the 'new hire' needs to run up the learning curve and fix the problem. You may notice that this argument assumes that the person who wrote the code originally is long gone and that there is nobody around who has ever touched the code that needs to be maintained. This assumption is based on observation.
"A supporting justification for using HLLs is that a compiled program will run as fast as the code the compiler generates can run. If you get a better compiler, the code will run faster (or smaller (or both)). It seems to be common practice to run existing code through new and better compilers as soon as they can be obtained. It is feasible that a sufficiently 'smart' compiler could take a problem stated in HLL and produce the simplest and fastest machine code possible for a given problem. The fact that such a compiler would take years to write, and perhaps take years to run is beside the point - heuristics coming into fashion it may yet happen. (I'm not holding my breath, though.)
"...why the UNIX boxes cost so much: the cost of goods
Page 14, Column 1
is a small portion of the real cost of a product. Most of the cost is the nickel and dime effect of all the other things that are needed to make the product attractive to the buyers. Little things like software, and support for the software. And marketing. And warehousing. And a mark-up so you get some profits. And...
"Unless a company gets to the point where it has a sufficiently large market share [like DEC? - FNE] that it can sell the product at a small profit margin, the price will have to remain high or the company will stay small." Steve M Long Beach CA
Steve, we are doing that backwards - our profit margin is small and the cost of goods is very definitely a major part of the cost of our boards. Although we are a small company, we are growing. And DEC does not seem to be cutting its prices the last time we looked. Perhaps there is a flaw in your logic?
About HLLS: today happens to be 30 Sep '83 and on the front page of the second section of the Wall Street Journal there are TWO stories which are strongly related to that subject. Some excerpts from the first:
"1-2-3 has become the most popular business program for personal computers... Companies that are ordering personal computers by the hundreds say they are beginning to place comparable orders for copies of 1-2- 3.
"Not surprisingly, competitors are taking note... Context, of Torrance, CA, is preparing a much faster version of MBA for release soon. [emphasis added]"
In other words, the Context folks are busily translating PASCAL into assembly, which is what they should have done in the first place. 1-2-3 and MBA are virtually the SAME PROGRAM, which is not surprising since Mitch Kapor has admitted that MBA was used as a model. If the Context folks had been smart enough to use assembly instead of PASCAL in the first place, THEY would have the "most Popular business program for personal computers"!
As it is, they are an also-ran and are having to (re)write their program in assembly anyhow. It is very important to be the FIRST, not the last, with an assembly language program!
If you follow the Wall Street Journal, you will know that Coleco's 'Adam' computer has been getting a lot of ink. Let us give you some inside scoop on Adam: the BASIC used in Adam is NOT Microsoft BASIC but a new BASIC written in assembly by Otherwise Intelligent's company. (Otherwise Intelligent is the guy who prefers the 16032 over the 68000 but is otherwise intelligent.)
Page 14, Column 2
O.I. tells us that it is the fastest Z-80 BASIC around and that it is being evaluated by a major software house (not Microsoft) for possible inclusion in their product line.
O.I. has also told us that the word processor for Adam is written in C, that the object code occupies 50K so that Adam can only hold about one page of text! And that the guys writing the word processor in C ridiculed O.I.'s outfit for not writing their BASIC in C! Among other claims, the resulting (C) code would be bug-free (of course!). Back to today's WSJ:
"The encounter started out as a cake-walk for Coleco" (when demonstrating their BASIC) "but... the word- processing program just didn't work as well as the programs work on many of the machines Coleco compares itself with.' Naturally! Those other companies have word processors written in assembly.
"The computer couldn't easily move text from the bottom of the screen to the top... Coleco executives conceded the system wasn't yet capable of 'professional' quality word processing. Don't worry, the executives said, the company will improve the word processing by early next year..." Yeah! Maybe Coleco will hire the Context folks to re-write the word processor in assembler as soon as Context has finished converting MBA from PASCAL to assembler.
The WSJ story on Adam is a LONG one and the focus of the story is an how lousy the word processor is. Now, neither the Coleco or the 1-2-3/MBA story specifically mentioned HLL or assembly but that is CLEARLY what those stories were about.
Look, folks, even Context has caught on. The WSJ is obviously alerted to the fact that some software is clearly superior to some other software, although they have not yet learned WHY. But some people are slower on the uptake than others. Distressingly to us, a few of the readers of this newsletter appear to be among those slower persons. (Not you, Steve; at least you are on the right track about getting rid of the slow stuff. And we don't think you were referring to mass- market software as we were/are,)
How much money has Context thrown away by sticking with PASCAL too long? How such has the applications programs and operating system (both written in PASCAL) hurt the sales of LISA? Apple is soon going to introduce Mackintosh, and we happen to know that a LOT of Mack's software is written in HLL (some is written in assembly). The WSJ reporters appear to be learning more quickly than the engineers at Apple!
The marketplace has ALREADY SPOKEN!
Page 15, Column 1
Grande REPORT:
As this is written, the first Grande owners have had their boards for a few days. We have already learned that we made a minor mistake with the demonstration software: although we personally modified the software and checked it out, we did so on an Apple which did NOT have a language card. Turns out some of the demos, notably SIEVE.H, won't work in an Apple/Grande system that does have a language card. Naturally, they won't work on an Apple IIe either. We should have the solutions to these little glitches soon.
The glitch with the language card almost certainly relates to the fact that the usual 68000 reset call (38383) also hooks into Applesoft in the language card - and if Applesoft ISN'T in the language card, well...
There is a minor hardware glitch as well: turns out the PAL memory decode chips - or at least one of then - has a logic error. We tried to map that spare 4K into $FDFXXX, and that won't work. We will soon send the early purchasers a replacement PAL which decodes that 4K into $FD0XXX, which DOES work.
We have tested the very-damn-hi-res graphics board with both the static and dynamic RAM boards, and we have also tested both boards with the prototype math chip board. As we expected, we do have compatibility between boards as far as the expansion interface is concerned.
The fact that the Grande expansion interface was laid out by literally tracing the layout of the GROUNDED board might possibly have something to do with that compatibility.
Although the Grande is out-selling the static RAM board as expected, sales are continuing steadily for the static board. What's REALLY surprising is that a Grande customer has ALREADY come back and purchased a static RAM board (with just 12K). Looks like he had a specific application that needed a small 68000 board.
Although we have done LOTS of memory testing - we have lost track of the exact number of megabyte/hours - we have yet to find our first 'soft' error. We have found two 64K DRAMs with hard errors - i.e. bad chip - out of the first couple thousand.
REMEMBER THE 2102?
Every time we buy a thousand DRAMs we get EIGHT MEGABYTES! (O.K., so the figure isn't exact.) We can remember buying large amounts of 2102s, but a thousand 2102s is only 128K. You know, back when we were buying 2102s, the words 'only' and '128K' were not used together. Times, they do change.
Page 15, Column 2
OUR GAME PLAN:
The Grande is just too good to be kept exclusively for Apple II types, especially with the 16081 math processor becoming available and with a static RAM compatible board available if needed. So we have to make the board available for use with other computers. Like the IBM PC and the CBM 64 and the CBM 8032. 8032??
Yes, 8032! At the urging of one of our customers, we have agreed to place no obstacles in the way of Waterloo if they want to bring up their 6809 SuperPet package on the 68000. Waterloo already have their package running on the 8032, which is why we would include the 8032 among that group. Besides, we have a few CBM type customers and an 8032 with the 80 column CRT and the 8050 and they are pretty nice pieces of gear. Also, we already are familiar with interfacing it. In this case, already being familiar is more important than already owning.
So why would anybody buy Grandes for the 8032, and another for the 64, and another for the IBM, and another for the Apple? Nobody HAS to! If you want to run your Apple/Grande on the 8032, and the 64, and the IBM, you will need just three simple interface boards - about $50 each - and three sets of demo software and other documentation - also about $50 each. The Grande is the same in each case. Make the interface board for the IBM $75 to $95; the IBM interface will be slightly more complex electrically and physically.
If you buy a Grande for the Apple, for another $100 you can run it (soon) on the 64 as well. Or for $125-$145 you can move over to the IBM PC. Soon.
What's holding us back at the moment is software. As soon as that problem is solved...
CRY FOUL!
One reader made a point of calling us up shortly after receiving issue #24 and strongly protesting our mistreatment of UNIX. His biggest complaint was that we were criticizing UNIX without having lots of personal hands-on experience.
How much experience do we have to have to note that UNIX has an exceptionally complex command structure, and that it requires a great deal of tine to learn? Or to note that a really good UNIX system costs $35,000 with one work station? Or that the UNIX REVIEW contains no information directed to the UNIX user - the person who gets his/her hands dirty an the keyboard?
A philosophical question: must one be able to play the violin, flute and flugelhorn to be a music critic?
Page 16, Column 1
Does one have to be a best-selling novelist to be a literary critic?
It is ironical that our conversation occurred on the day Electronic News arrived with a LONG article on upper-end small computer operating systems. The article was focussed around Jean Yates, who is a UNIX person. Jean says UNIX is not doing as well as she had earlier expected. The article also asserted that the mainframe folks are getting real interested in UNIX. You betchum! UNIX, like a mainframe, is something that gets done to you whether you like it or not. The poor sucker hit with that 600 page manual has the same freedom of choice as a keypunch operator.
Actually, our comments on UNIX are based not only on our own personal observations, but on consultations with a couple of heavy-duty, gung-ho UNIX types, the ones who use their UNIX-based computer 8 hours a day, five or six days a week. Neither of them will reveal whether their employer permits them to break for lunch. These types seem to believe (as does the irate caller, we believe) that UNIX will arrive, eventually, but that you will not recognize it.
They describe to us yet another 'shell' which makes a UNIX system as simple for a clerk to use as, say, the operating systems of the Pets/Apples/Trash-80s. Our question: if we get such a simplified operating system, how come we still have to give Western Electric a 70-pound bag of gold for permission to use it?
If you are a UNIX fan, here is something that might worry you: Jean had her market forecasting firm, Yates Ventures, project sales of the various 16-bit operating systems up through 1986. Jean, who is very definitely a UNIX person, was able to predict that UNIX would do better than only ONE operating system: Pick! She thought all the others would do MUCH better - and so do we! Who says we never agree with the UNIX experts?
One supposes that Jean has not noticed that Pick is the ONLY operating system in the group that is more expensive than UNIX. One also supposes that Jean has not noticed that the two 16-bit operating systems which she is predicting will have the fewest installations are the two which are purchased by honchos for use by peons, while all the others, which she is predicting will be most successful, are purchased by the person(s) who will use them.
Fifteen years ago 100% of all computers purchased were purchased by honchos for peons to use. Current predictions are that 1985 will be the year that personal computer purchases will surpass mainframe purchases in absolute dollar volume. If UNIX is going to become successful it had better become successful FAST because the clear trend is away from computers
Page 16, Column 2
bought by honchos for peons, which is what UNIX is about. Make that a clear, RAPID trend!
If you are selecting an operating system for your own use on a computer you are going to purchase for your own use do you want one which is optimized for a single user - you - or one which is optimized to share a single CPU amongst a number of workers in an office? Is this a real choice?
PROGRAMMING CONSIDERATIONS:
While the 16081 is significantly faster than the Intel 8087 for loads, stores, and the four fundamental mathematical operations, the Intel chip has the advantage that some transcendental are performed entirely internally. As a result, the 8087 can calculate a logarithm in about 212 microseconds (9 load, 3 load internal constant, 180 log, 20 store). We assume that this figure, which was given to us by an Intel type with the accompanying challenge: "How long does it take the 68000/16081 to do this?" is for double precision calculations. All of the discussions here will be exclusively for double-precision operations.
We will assume that you have read pages 19 and 20 of issue #18, in which we point out a misprint in Hart, et al's Computer Approximations and the necessity to convert the constants given in Hart. We will proceed directly to the assertion that (one method of) computing the logarithm function involves reducing the range of the argument to:
SQR(.5) =< X < SQR(2)Then calculating Z and Y such that:
Z = (X-1)/(X+1) Y = Z * ZThe partial logarithm (of the reduced range) is then computed from:
LOG(X) = Z * P(Y)where N = 6 and the constants are given either by Hart 2665 for base e or Hart 2305 for base 10. These constants must be converted for calculation of the log base 2. We are using Y rather than [Z squared] as Hart does because we can't print superscripts. If you do not know what P(Y), N = 6 Or Hart 2665 means, we suggest that you read pages 10 - 14 our newsletter #16 and pages 19 and 20 (at least) of our newsletter #18.
Let us assume that we have already computed Z and stored it in one of the 16081's eight internal registers and have computed Y and stored it in another
Page 17, Column 1
register. P(6) thru P(0) are seven constants which will be stored in the 68000's memory.
When we say "mult" or "add" with only one operand, the F.P. accumulator of the 16081 is the implied second operand, and the result is left in that accumulator. We begin with Y in the accumulator (as well as in a 16081 register). Here is the sequence required to compute Z * P(Y):
MULT P6
ADD P5
MULT Y
ADD P4
MULT Y
ADD P3
MULT Y
ADD P2
MULT Y
ADD P1
MULT Y
ADD P0
MULT ZYou will note that there is a considerable repetition of "MULT Y, ADD Pn." We reported last issue that it required the 68000/16081 combination 23 microseconds to perform the operation A = B * C where A, B and C are located in memory. Much of that time was required to move the two operands into the math chip and to move the result from the math chip back into memory. However, "MULT Y, ADD Pn" involves moving only a single operand (the constant Pn) into the math chip; the result does not need to be read out until the end of the calculation sequence. Here is a crude way to perform the sequence above:
MULT P6
SET CTR
BRA BB
AA MULT Y
BB ADD Pn
DEC CTR
BNE AA
MULT ZIt would appear that the above sequence would add the loop overhead, about one microsecond per loop times six loops, to the time required to calculate the LOG function. But with a little forethought we should be able to avoid that, and also cheat the Yon Neumann bus- bandwidth problem. How? By overlapping 68000 and 16081 operations, of course. Let us provide same details of the inner four instructions above, including overlapped operations:
Page 17, Column 2
AA WAIT UNTIL ADD IS DONE
SEND "MULT Y" COMMAND SEQUENCE
SET UP ADD COMMAND SEQUENCE
FETCH Pn INTO 68000 DATA REGS
WAIT UNTIL MULT IS DONE
BB SEND "ADD COMMAND," then operand Pn
SET UP "MULT Y" COMMAND SEQUENCE
DECR COUNTER AND LOOP TO AA IF > 0What we are doing in the sequence above is using the multiply time to fetch the two words (ID, COMMAND WORD) and the four-word operand into 68000 data registers. By overlapping a total of six memory cycles, we save about two microseconds per multiply and perhaps a similar figure for the add. Since we execute the loop six times, we have saved about 24 microseconds by overlapping functions.
In the next newsletter we will provide actual source code and timing for a complete 68000/16081 logarithm computation. It will be interesting to see how closely we can approach the 212 microsecond timing of the 8087.
MATRIX INVERSION TIMING:
The simple dyadic timing comparison we have already done proves that the 68000/16081 can invert a matrix three times faster than the 5MHz 8006/8087, and perhaps even faster than that with some instruction overlapping. This timing comparison would be such more relevant to, say, a structural analysis program than the time to calculate a logarithm.
PHASE ZERO REPORT:
We may owe PHASE ZERO an apology. We assumed MINOS 1.0 was mostly 6502 code because of a letter (excerpted in the last issue) from the guy who wrote it. We have just been informed by a different PHASE ZERO type that MINOS is in fact mainly written in 68000 code! Right now we are confused (this is news?).
PUBLICATION DATES:
In a properly-run world, all monthly publications would be mailed an the last day of the month preceding the date on the cover and delivered the next day. You have maybe noticed that the world is not properly run. This newsletter and the Jeffries Report are engaged in an informal competition. We mailed our September issue (for instance) around 22 Aug while the September Jeffries Report will probably be mailed around the 9th of October! If this trend continues, we may mail our Jan. issue before Ron mails his Nov. issue!
If we are going to try to stay monthly for a while, we need to get a little ahead. Has anyone noticed that we
Page 18, Column 1
usually require 60 days to throw together an issue around NFL playoff time? All those football games (the bowl gases, too) really cut into the time available for this newsletter
If Ron isn't a football fan, our situation may be reversed before long.
THE SPEED OF RADIO
is, of course, the same as the speed of light. Unfortunately, that isn't all that fast and in fact is painfully slow at times as we can personally attest. When we call overseas, such as England, we almost always get a satellite voice channel link. Let us tell you, a satellite voice link can be an unnerving experience. In normal conversation each of us (you and we) depend upon pauses in the conversation as signals for the other to start talking. If the pause is longer than usual each of us, you and we, take that as a signal to resume conversation, the 'token' having been returned to the sender. (A little networking joke there, folks.) The problem is, the substantial delay to send the voice channel four times the distance from the Earth to 24-hour orbital height before the signal returns to the sender stretches the normal 'over to you' pause into an imagined 'back to me; the token has been returned' pause.
What that means is that even experienced transatlantic conversationalists are constantly stepping on each other's lines. This is highly inconvenient even when one knows what is going on. For the beginner who does NOT know what is going on, it can be a frustrating and even infuriating experience. One can easily get the impression that the person at the other end of the line is an uncooperative, arrogant bastard. Which may, of course, be true but not for the reasons believed.
The thing is, some voice traffic - said to be 25% - is still carried by underwater cable. (You remember transatlantic cable, don't you?) If you are fortunate enough to get a cable connection across the big creek, perfectly normal conversation is possible with no apparent delays. We got such a connection on Oct 1 when Ulrich S called us from Aachen, W. Germany. Paradise always has a snake, though. We lost small parts of Ulrich's conversations early in the call and then he finally died out altogether at the end and we had to hang up. You see, those underwater cables use vacuum tube repeaters. Yes, vacuum tubes! What do they use these days in new cables? WHAT new cables?
TAKE THAT, FNE! DEPT:
We are pleased to report that a number of you have taken the time to write us and inform us that we are all wet (bowdlerized) regarding high-level languages
Page 18, Column 2
(HLL) vs. assembly. The arguments feature transportability, productivity, maintainability, proper structure and some other stuff which we already know about (honest). Regrettably, all of the letters discuss the matter from a standpoint of pure theory. If YOU have written one of those letters, here is what you have overlooked:
You have failed to test your theories against the real- world marketplace. In the properly-run world which you describe, Context's MBA would be selling better than 1- 2-3 because it is virtually the save program, only programmed correctly (by your viewpoint) in a structured, transportable, maintainable language.
Now, look: your FNE can be, and has been, wrong. But the marketplace is NEVER wrong! Tens, if not hundreds, of thousands of consumers are voting with their wallets and assembly is winning in such a landslide you'd think the election was taking place in Leningrad!
Can any amongst you offer a HLL-vs-assembly theory which conforms to the real- world marketplace? If our assertions conform to the real-world marketplace and yours do not, which of us is most likely correct?
MARKETPLACE MESSAGE #1:
The Oct 6 issue of EN reports that Apple has laid off 55% of its production line workers in a Carrollton, TX plant which manufactures LISA. This follows a report the preceding week that LISA production was terminated at the Cupertino, CA plant and all work transferred to the Carrollton plant. Apple's actions are a clear response to an equally clear message from the real- world marketplace.
Is it a coincidence that LISA is "supported" by (according to Softalk magazine) 900,000 lines of PASCAL?
MARKETPLACE MESSAGE #2:
The Fortune Systems board of directors held an unscheduled meeting on Oct. 4 and forced President Gary Friedman to resign. One may assume that Friedman's forced departure was NOT caused by excessive sales and profits.
The Fortune 32:16 features an operating system written in HLL and a Basic interpreter written in C. The Apple II running Applesoft - known as Applesloth in some circles - flat beat the 32:16 when Interface Age reviewed it a long spell ago.
Page 19, Column 1
MARKETPLACE MESSAGE #3:
The next day, the Wall Street Journal reported that Commodore sales for the third quarter will approach $300 million, and that demand for the 64 exceeds production by 25% even though 100,000 64s are being produced each month. You can't get a such clearer message from the marketplace than that.
The WSJ predicts : "(the 64) is selling so fast it will probably be gone from retailer's shelves by the end of November." Now we have the problem of convincing you that our other report on Commodore elsewhere in this issue, where we suggested you buy your 64 before Xmas, was written before we read this WSJ article...
AMUSING STUFF:
That same WSJ article we just mentioned states that: "(Commodore) turned away a distributor who arrived at its Pennsylvania plant with a tractor-trailer and a $500,000 check, hoping to buy 2,500 model 64s and some extra equipment." They didn't get them.
MEETING NOTICE:
The 55% of the LISA production workers who have just been laid off have invited Gary Friedman, former President of Fortune Systems, to give a talk on "The Advantages of High Level Languages." Carl Helmers will be the master of ceremonies. After the talk, there will be a sneak preview of Mackintosh, including a demonstration that Mack's BASIC is nearly as fast as Applesloth, er, Applesoft. The meeting will be held in the closed-off portion of the Carrollton plant which used to be occupied by LISA production lines.
IEEE COMPUTER WATCH:
The latest issue of COMPUTER (Oct '83) is dedicated the the subject of 'knowledge representation', which is a particular aspect of artificial intelligence. We conclude that artificial intelligence has a long way to go; you might feel differently. If you are interested in artificial intelligence, make an effort to review this issue of COMPUTER magazine.
ALGORITHM OWNERSHIP:
We hope that all of you realize that it is perfectly proper to copy an algorithm. Otherwise, if you added two and two and got four for an answer, somebody could sue you. (This issue was decided a long time back by the U.S. Supreme Court in a suit involving IBM's desire to lock up a binary-to-BCD algorithm, or maybe BCD-to- binary.)
BYTE WATCH:
Page 19, Column 2
First, we want you to know that we did NOT write the letter in Oct '93 BYTE magazine about the Tandy Model 16 68000 BASIC being ungodly slow. We loved the official reply from Tandy, which never once mentioned that the BASIC was written in C.
Oct. Byte has about nine articles on UNIX. One is by David Fiedler, who writes a newsletter for the UNIX folks. On page 152, David argues that any operating system which can only support a single user is worthless and is to be rejected in the search for a universal operating system. He seems to think that MS- DOS 2.0 is a win for UNIX. It is absolutely amazing how wrong-headed newsletter writers can sometimes be.
First, 1985 is the year when personal computers (that's the single-user kind, David) are going to pass mainframes and minis combined in total dollar volume. With personal computers moving up (the 68020 will be available over the counter in 1985, and that chip is a genuine VAX-killer!) and mainframes moving down (have you seen the latest IBM releases?) computers in the $30,000 - $300,000 area, which is UNIX's niche, are gonna get squeezed badly.
Second, David seems to feel that MS-DOS, which has adapted hierarchical file structure (a noted UNIX feature), will naturally support multiple users, beginning tomorrow. Therefore, MS-DOS is really UNIX! Sigh. Look, guys, hierarchical files are no more an exclusive property of UNIX than threaded code is an exclusive property of FORTH. An hierarchical file structure is REQUIRED once enough files are at hand.
Don't you readers keep your floppy disks with text files separate from the BASIC programs which are kept separate from... that's an hierarchical file structure, guys! If you have a big hard disk you will naturally place all your files on that big hard disk and then your hierarchical structure has to be in the disk operating system. Did we ever tell you that real UNIX REQUIRES a big (and fast) hard disk? To repeat, the hierarchical file structure is required by the big disk and is not an exclusive property of UNIX.
Third, MS-DOS is written in assembly, NOT C! As a result, MS-DOS gives excellent performance with a relatively inferior microprocessor whereas UNIX, written in C, requires the best microprocessor available in order to provide adequate performance,
Do not kid yourself that Bill Gates does not know the difference in performance between an operating system (or BASIC) versus the performance when written in C. It is absolutely no accident that the operating system and BASIC which Microsoft wrote to support its highly profitable relationship with IBM are written in assembly, and that its 68000 BASIC is written in C.
Page 20, Column 1
YESTERDAY AND TOMORROW:
About fifteen years ago we bought our first programmable calculator. It was a Wang 500 with an entire 1720 programmable steps and sixteen floating- point registers. The programming language was exceptionally compact and efficient since only a four- bit field was needed to determine the address of the register. Naturally, nobody was expected to know hexadecimal in those days so the 256 possible step codes ranged from 00-00 to 15-15, which these days we would call $00 to $FF. For register operations, the first nibble specified the operation and the second specified the register.
01-XX = Total register XX
02-XX = Add " "
03-XX = Subtract " "
04-XX = Multiply " "
05-XX = Divide " "
06-XX = Store in " "
07-XX = Recall " "Program steps beginning with 08 or 09 were built-in subroutines called LOG, or TAN, or ARCSIN. Program steps beginning with 10 or 11 were one of the 32 user- definable subroutines. Because the user memory was small, a user subroutine could be called with a single programming step or byte, say, 10-00. The machine would then search through the program memory, all 320 bytes of it, looking for a "MARK" or "LABEL" byte, followed by the 10-00 identifier. Once finding that two-step identifier, it would begin executing the programming steps immediately following the identifier.
One of the things we did with this machine was write a program to calculate the wire sizes and the number of turns for a power transformer. Since the company we worked for (and held a substantial equity interest in) manufactured AC power sources, transformer design was a frequent and very tedious job done using tables and a slide rule with several iterations required to refine the job. This was especially true if there were several taps on the secondary winding, as was usually the case. It was VERY common for mistakes to be made; and transformers that are made incorrectly must be paid for and then junked and re-ordered, which delays shipment and reduces profits.
After writing the transformer design program (which was stored on digital tape cassette) it was very rare for transformers to be misdesigned and a task which was formerly tedious and time-consuming became quick and almost trivial. We decided that computers were here to stay. We left that company in 1972 but the Wang 500 and the transformer design program were still being used as recently as three years ago and may, for all we know, be in use today.
Page 20, Column 1
Two or three years after we bought the Wang 500 at work we bought a Wang 520 at hose. The 520 had 1,848 programming steps! In addition to the 16 scratch registers, it had up to 231 additional floating point registers that could be obtained by swapping 8 programming steps (goodby Harvard, hello Princeton!). Naturally, with the vastly superior memory and data storage available, far more complex problems could be solved, right?
Well, yes (stated in a subdued fashion). But not so more advanced as the ratio of 1848 - 320 would imply. First, just one nibble was no longer adequate to specify one of those 231 extra register. And because there were only 256 possible program codes, you had to LOAD one of those registers into the accumulator - two steps - perform some math operation using data in one of the scratch registers, and then STORE the register - two more steps. So there was an overhead of four program steps that had to be paid to manipulate one of those registers on top of the mathematical operations involved. As these facts became apparent, our enthusiasm over the vastly larger memory space that came with the 520 was muted...
WHA HOPPEN?
What basically happened was that we discovered that the amount of program space to perform a given operation doubled because 1) eight bits were needed to specify a register, not four and 2) two bytes were (often) needed to specify an operation instead of one because the number of possible operations was greatly increased by the additional memory. Thirty-two subroutine labels are no longer enough, to give another example.
4 bits = 16 registers
8 bits = 256 "
16 bits = 8192 "
24 bits = 131072 "
32 bits = 1/2 billion " !If you are paying attention, you will notice a discontinuity between the number of registers definable by 8 bits and 16 bits. That's because when the number of registers becomes sufficiently large it is necessary to specify the register by its absolute address in memory rather than by the register number.
Our old friend the 6502 (or Z-80) is right in the middle with up to 8,000 (double precision floating point) registers addressable. Next up at 24 bits we find the Motorola 68000 and the Nat Semi 16032, both of which are intermediate steps on the way to true 32-bit machines which are able to directly address half a billion registers. Can you truly imagine that? FIVE HUNDRED MILLION REGISTERS? We did some VERY useful work with just 16!
Page 21, Column 1
Let us offer this hypothetical scenario: Suppose that it was our neighbor, not us, that moved up to the 1848- step Wang 520 and we were stuck with our 320-step 500. We could have presented to pretty good arguments for our 500. We really DID do LOTS of useful things with it. The language was HIGHLY efficient. The arguments we would have presented would have been truthfully believed in by us. The 'efficiency' part we still believe in! And the word 'efficiency' would have appeared very frequently and prominently in our argument...
TOMORROW AND YESTERDAY:
This past week an Intel type person spent about 45 minutes, long distance on his nickel, trying to convince us that the 808X was superior to the 68000. He argued that addressing with 16 bit address pointers was superior (certainly more EFFICIENT!) to the use of 24 or 32-bit pointers. He argued that it was a natural law of the universe that code be written in modules sized 64K or smaller. The word 'efficiency' appeared over and over in his arguments. He repeatedly asserted that 68000 code would inevitably be larger than 808X code for a given function, which happens to be true.
All of his arguments corresponded one-to-one with that 500 vs. 520 argument (which never occurred). The 500 code IS more efficient than the 520, and 808X code IS more efficient than 68000 code. It is nevertheless true that the 520 was significantly superior to the 500, and that the 68000 IS significantly superior to the 808X. An inevitable result of this superiority is a decrease in code efficiency. It is such more efficient to address a floating point register using four bits than 32, but the 32-bit machine is inherently vastly superior.
In microprocessors, capability goes up as code efficiency goes down and vice versa!
THE OP CODE FIELD:
In the 6502, all op codes are one byte long. The vanilla 6502 has just 156 instructions, which is a good fit for a one-byte op code field. We believe - although we are not certain - that all of the 8080 op codes were one-byte codes. (Naturally, both microprocessors had many instructions which carried along parameter fields so that the total instruction might be two or three bytes. Nevertheless, the op code is just a single byte.)
When Intel decided to make an early move into the 16- bit arena they were limited (as all chip makers were and are) in the amount of resources, such as registers and such, that they could put on the chip. And, they wished to maintain COMPLETE functional compatibility
Page 21, Column 2
with the 8080 so that code written for the 8080 could be translated into 808X code. As a result, the 808X has many op codes which are one-byte codes.
We trust it is apparent that if one has 256 one-byte op codes then one cannot have ANY op codes which are longer than one byte? And that 255 potential 16-bit op codes are permanently lost for each one-byte op code? And that devices which have some one-byte op codes can have much more compact code than a device which has 16- bit op codes as the shortest available?
If you have 16 registers, not 231, you can get by with a 4-bit register address field. Since the 808X has only 25% as much internal resources as the 68000, it can get by with one-byte op codes. That's more efficient. Since the Wang 500 has only 16 registers it can get by with only a 4-bit address field. That's more efficient.
THOSE 64K CODE MODULES:
In the past fifteen years, almost all computer scientists in universities have been limited to hands- an experience with minicomputers having a 16-bit address field. When memories larger than 64K came along, segmentation was the only way to use those larger memories. Code was indeed written in 64K (or smaller) modules, but out of absolute necessity rather than as a law of the natural universe. If one is working with the PDP11/70 or an Intel 808X, one is STILL limited to the necessity of coding in 64K modules. The argument presented by the Intel type was that this was more efficient (correct) and therefore desirable (incorrect).
As we reach and proceed beyond each boundary of address space it is inevitable that there will be a backlash, a natural resistance to continue onward. Four bits are enough to address 16 registers but it is highly inefficient to use eight bits to address 17 registers! The inefficiency of moving to larger address fields (or op codes) is REAL! It is also NECESSARY, if we are not going to program with 16 registers and 320 program steps forever. Many of the arguments presented by the Intel type were absolutely correct but the point of the argument, that the 808X was superior to the 68000, was dead wrong.
The 8088 has an 8-bit data bus, 8-bit op codes, 16 bytes of internal registers and a longest operand of 16 bits. The 68000 has a 16-bit data bus, 16-bit op codes, 64 bytes of internal registers and a longest operand of 32 bits. It is true that both the 808X and the 68000 have 16-bit multiplies and divides. Based on these facts, that Intel type had the nerve to assert that the 8088 and 68000 were both 16-bit microprocessors, the SAME size! Unbelievable!
Page 22, Column 1
ARGUMENTS FOR THE 808X:
As we have said, efficiency is a REAL issue. Moving just slightly beyond 64K is problematic, as many of you with Cram-apples or Legend Industries memory expansion in your Apples have discovered. In our opinion, the Intel 808X architecture is indeed optimum for memory configurations up to 192K. That gives you 64K for your machine code, 64K for your high level language code, and 64K for your high level language data. In our opinion the 808X is the right 'engine' for the 'over 64K' to 'under half a meg' machines.
A long time back (issue #11, p.7) we presented evidence to support the assertion that the amount of memory that can be purchased using constant dollars doubles every 18 months. We also pointed out that everyone will always have as such memory as he can afford, given the urgency of his/her application and/or motivation. We believe that we can make the general assertion that the typical hacker will have about four times the memory of the rock-shooter and that the serious enthusiast will have about twice as such as the typical hacker. Let RS = rock shooter, TH = typical hacker and SE = serious enthusiast. See if you agree with the following schedule:
DATE RS TH SE
---- -- -- --
1/78 4K 16K 32K
7/79 8K 32K 64K
1/81 16K 64K 128K
7/82 32K 128K 256K
1/84 64K 256K 512K
7/85 128K 512K 1 MEG
1/87 256K 1 MEG 2 MEGThis chart indicates that a serious enthusiast would have logically become interested in the 808X in July 1979 and have switched interest to the 68000 (or 16032) sixteen months ago - which oddly enough is when DTACK sales took off after lingering in the doldrums for the first seven months. We see your typical hacker becoming interested in the 68000 in a couple of months, while the rock-shooter will be well pleased with the Intel architecture until 1987.
What's that? You say the 808X can address a MEGABYTE? True, it can do that in a very inefficient and clumsy manner (segmentation). The reason the 808X works O.K. up to 192K (or sometimes 256K) is that four of its
Page 22, Column 2
eight registers have been dedicated to work with a particular segment pointer. As a result, Softech PASCAL 4.1 is limited to 64K of program and 64K of data, and IBM's PC BASIC is limited to 64K of program and 64K of data (Aha! You didn't know that, did you?). So what are the PC folks who have loaded up their system with 512K DRAM doing? Mostly, they are doing a lot of bitching about the limitations imposed by the Intel architecture, that's what!
And Softech's 68000 PASCAL is crippled by being limited to 64K program space and 64K data space as a sacrifice on the altar of the great god TRANSPORTABILITY!
And the arguments we have prevented suggest that the 68000 really is not a sensible processor to use until one surpasses 192K RAM, or until one clearly foresees surpassing 192K! And since there are a lot more typical hackers than serious enthusiasts, that schedule above suggests that our sales might increase noticeably quite soon. The fact that DTACK-PASCAL support is now a reality and the DTACK-FORTRAN is on the way from TWO sources (one of them p-code) in the next few months, plus HALGOL and PHASE ZERO BASIC, is totally irrelevant to our argument (of course!).
The fact that the DTACK Grande has by far the best performance/cost ratio of anything even remotely in its class is ALSO irrelevant to our argument (of course!). Oh, yes: we shipped 6 megabytes' worth of Grandes on 28 Sep '83, that one day. The three guys (no gals) who have full gallons are 21 months ahead of schedule...
RUMORS MONGERED HERE:
There are a few chip designers and sellers at Intel (the rumor goes) who would like to shoot Bill Gates right now. It seems the Microsoft folks can't read, and as a result Intel has a large pile of 80188s it can't ship. And Intel is redesigning the 80188 chip. Again.
It's like this: the 8080 spec sheet reserves two of the 256 jump vector addresses for future Intel use. Microsoft went ahead and used them in the MS-DOS operating system anyway. The large pile of 80188s that Intel can't ship use those two reserved vectors for a hardware purpose. Understand, now, Intel was right and Microsoft was wrong. And: true, Microsoft could modify MS-DOS to comply, retroactively, with Intel's entirely correct documentation.
Unfortunately, there are about 12,000 application programs sitting on computer retailer's shelves all over the country which call those vectors... It would seem that in this case Intel's substantial software support backfired.
Page 23, Column 1
Since Intel's documentation scrupulously documented that those two vectors are reserved, they are (the rumor goes) refusing to take back the 80188s it has sold, unless (the rumor continues) the customer uses a blue logo with three alphabetic characters.
And now you know why Peanut has not been shipped yet, and what CPU Peanut uses. We wonder how long it will take Intel to change the mask - again - and get the chip back into production - again? (Do you realize that most folks don't know why Peanut hasn't been released but YOU do?)
And you also know why the Intel folks would like to shoot Bill Gates. (If the rumor is correct.)
HERE ARE THE FACTS:
The following information was gathered from the Intel iAPX 86/88, 186/188 User's Manual, Intel #210912-001, pages 4-10 and 5-5; and from the IBM PC XT Technical Reference Manual, page 2-4. Page 4-10, shows that the 8088 has 5 (five) dedicated interrupt pointers (#0 - #4), 27 reserved interrupt pointers (#5 - #31), and 224 (user) available interrupt pointers (#32 - #255).
Page 2-4 of the IBM manual reveals that MS-DOS uses 25 of those 27 reserved interrupt vectors. Specifically, MS-DOS uses #5 and #8 thru #31 inclusive.
Now turn to page 5-6 of the Intel manual. Table 5-2 reveals that the 80186/8 uses #5 as a vector for the array bounds exception, and also vectors #6 thru 15 and #18 and #19. Which means that MS-DOS programs will NOT, in general, run on the 80186/8. We are told that the better the program, the more likely that those MS- DOS vectors are being used at the application level.
The fact is that the 80186/8 is a very cost-effective chip at the hardware system level, as we have reported before. It is highly logical that IBM would, given enough lead time, use the 80186 in a highly cost- sensitive device such as a home computer. Let us assume that this tiny, trifling conflict was discovered very late in the design cycle for Peanut (in large companies, the hardware and software types sometimes don't communicate well). We can think of four ways out of the dilemma:
- Cancel Peanut.
- Go to market with a product that won't run all those MS-DOS-based PC programs out there.
- Re-design Peanut to use the 8088 - an expensive and time-consuming alternative involving a complete re-layout of the main circuit board.
- Get the company which you own a large piece of to take back all those 188 chips IBM (may) have bought and re-design the 188 to conform to MS-DOS. This is also time-consuming but the expense is placed elsewhere!
Page 23, Column 2
We would like to thank Otherwise Intelligent for the rumor and Harry S, who is affiliated with a networking firm, for his help in piecing the facts together.
PERMISSION TO RECOPY:
Permission is hereby granted to anyone whomever to make unlimited copies of any part or whole of this newsletter provided a copy of THIS page, with its accompanying subscription information, is included.
But if you give somebody a photocopy please remind them that there will be more hardware information and ESPECIALLY more software information about the 68000/16081 combination in subsequent issues!
THE FOLLOWING TRADEMARKS ARE ACKNOWLEDGED: Apple, II, II+, IIe, soft, LISA: Apple Computer Co. Anybody else need a 166th million ack, have your legal beagles send us the usual threatening note. (To the best of our knowledge, Apple has not trademarked Mackintosh yet. We don't have a THING planned for tomorrow; we just might mail something to the trademark registry office just for the hell of it. With trademarks, it's first come, first served.)
SUBSCRIPTIONS: Beginning with issue #19, subscriptions are $15 for 10 issues in the U.S. and Canada (U.S. funds), or $25 for 10 issues elsewhere. Make the check payable to DTACK GROUNDED. The address is:
DTACK GROUNDED
1415 E. McFadden, Ste. F
SANTA ANA CA 92705
REDLANDS IS BACK? Yes! It's just that REDLANDS is about a hardware subject for the first, but not last, time. Who said there is nothing new under the sun? Next month we will provide some software demonstrating how to use the 16081 to calculate one or more transcendental functions and what the timing is compared to the Intel 8087. We also expect to provide, in the near future, comparisons of transcendental function (in)accuracy between the 8087, 16081 and our own 62-bit F.P. package (REDLANDS in issue #15 & #16).
To the best of our knowledge, nobody has ever looked at the inaccuracy of the 8087's built-in transcendental functions except Dr. Dobbs' Journal, reported elsewhere in this issue. The results reported by Dr. Dobbs are, um, interesting. Stick around; it looks like we - that's you and us - are gonna have lots of fun!
Page 24, Column 1
THE NATIONAL 16081
The 16081 was originally designed to be used both as a tightly coupled coprocessor to the 16032 and as a peripheral for other processors, the objective being to increase the sales potential of the part. Preliminary specification sheets clearly revealed this intended use.
But as the 16081 neared production status it seems that there was a reversal of this strategy, which we think involved a marketing victory over engineering. Imagine this scenario:
Enter a high priest of marketing, accompanied by flacks, copy writers and other sycophants. Imagine the scene when the marketing type discovers that the new math chip could be loosely coupled to foreign CPUs: a swollen neck, steam escaping from ears, clenched fists and bloodshot eyes.
"What the hell do you guys think you are doing?" he shouts. "Here we have an advantage in speed over Intel and an advantage, period, over Motorola and YOU," (here strangling noises are heard), "YOU are helping both of our competitors? You will re-write that application information, NOW, to obscure the fact that our competitors can benefit from" - this delivered with an expression of unbearable disgust - "our OWN efforts!" Exeunt caster marketer and sycophants, stage left.
So a new specification/application sheet has been released which does not even whisper about the possibility of using the 16081 as a loosely coupled device. The following assumes that the 16081 is in production, which it ain't yet:
The competitive situation settles out in this manner: Intel has the slowest microprocessor and one which is incapable of addressing more than 64K bytes at a time, but has the 8087, which has been around long enough to attract some software support. National has a microprocessor which does not have the addressing limitations of the Intel part and which, in addition, has superior performance to the Intel part for non- floating point operations and ALSO significantly superior performance - say, three times faster - for floating point operands. And there is Motorola, featuring the same unlimited addressing capability as National and (due to a 12.5MHz vs 6MHz clock) more than double the non-floating point performance of the National parts BUT (alas and alack) no math chip in sight anytime soon.
And since there is no math chip, whether loosely or tightly coupled, available for use with the 68000, it will naturally lose a few designs to other devices, right? Well, that will be correct if all 400 of our
Page 24, Column 2
subscribers keep the contents of this newsletter a deep secret. You see, we are going to reveal how to use the 16081 with the 68000, and how to do so even more efficiently than when tightly coupled to the 16032!
You WILL keep this a secret, won't you?
DO NOT REVEAL
that the 16081 has only 24 pins, 16 of which are used for data and two of which are used for ground (the output buffers have an independent ground pin) and one for +5. Since we are pretty sure that the hardware hackers amongst you know all about those 19 lines, that leaves only 5 more to worry about. One of those five is a reset pin. You program that low to reset the 16081 and set up some default parameters that you can read about in the spec sheet. It turns out that the designers have done a good job and the default parameters are the ones you will want, so don't worry about them. We're lazy, so we just wire this in parallel with the reset pin on the 68000. Now we are down to four pins,
One of the four remaining pins is a clock input. The spec sheet lies about this pin, saying the clock can be asynchronous. That is not in accordance with the facts. The clock we are using is the 68000 clock, divided by two. That's definitely not asynchronous. We will discuss this in more detail later, but for now just run your 68000 clock through half a 74LS74 to divide it by two, and feed it into the clock pin on the 16081. We are now down to three pins (this thing is real complicated, folks!).
Two of the three remaining pins are really address pins which permit accessing one of three functions inside the 16081. National calls them status lines for some reason; ST0 and ST1 to be exact. You could, if you wish, attach A1 and A2 to ST0 and ST1, respectively. You would then have to map the 16081 into a four-word (eight byte) memory space. That would work quite well for a simple design using word MOVEs only. Use A2 and A3 if you want to use long word MOVEs and use A5 and A6 if you want to be able to move two floating point operands with a single MOVEM.L instruction. Since the 68000 has lots of memory space for now, the obvious choice is A5 and A6. There is only one pin remaining.
The last pin is (bar) SPC, which is like a chip select except that it is also an output, so it has to be driven by an open collector device such as a 74LS09. We suggest a 1K external pullup be used. When addressing the 16081 the SPC pin acts like a perfectly ordinary chip select input. HOWEVER - and this is the only tricky part, aside from the use of a synchronous clock - the 16081 signals the completion of an operation by pulsing this pin low for one clock cycle.
Page 25, Column 1
We want to capture that pulse and turn it into a level that the 68000 can recognize. So we use the other half of the 74LS74 we divided the clock with to capture that pulse. If we invert the signal on the SPC pin we can save 167 nanoseconds in recognizing the 'done' signal.
Finally, we have to reset that LS74 every time we address the 16081, and we have to be able to read the 'done' bit, so we need a one-bit tri-state buffer attached to B15 (B for bit so as not to be confused with D for data register). This tri-state buffer has to be mapped into a separate location than the 16081 itself since a read or write into the 16081 space will cause the 1/2 LS74 to be reset. There are no pins remaining, so now you know how to construct a 68000/16081 system!
But remember - this information is a secret.
The information above is all that is needed to design and construct a simple 68000 system with a 16081 floating point math processor as a conventional peripheral device. Before discussing some design enhancements, let us linger over some additional information about this simple system:
THAT ASYNCHRONOUS CLOCK
that really isn't: Our initial prototype used a conventional 12.5MHz DTACK GROUNDED static RAM board interfaced to a 6MHz 16081 via the expansion connector. The prototype 16081 board had its own 24MHz crystal oscillator divided by four using the two halves of a 74LS74. When we initially ran 'single-event' tests on it it worked fine. But when we put it in a repetitive loop to time the operation A = B * C, it would 'hang up' after about 20 milliseconds an average, or once every 800 operations. We decided this was due to the speed of the 12.5MHz, which permitted word stores and fetches to take place in less than two full clock cycles of the 16081.
So we modified the DTACK board to run at 8MHz. The system still 'hung up' after an average of 20 milliseconds! Then we brought the 68000 clock, back at 12.5MHz, out to the prototype board and ran it through 1/2 an LS74 to get a 16081 clock of 6.25MHz, but synchronous with the microprocessor clock. This worked fine and has never hung up, even after several hours (about half a billion floating point operations!). Here is our conclusion:
A data word fed into the 16091 must be removed from the input buffer to make way for the next data word (in general). This MUST be done synchronously with respect
Page 25, Column 2
to the 16081's clock, no? This clock, if asynchronous, can occur with any phase relationship whatever with respect to the SPC pulse which stores the data. Given a clock rate of 6MHz for the 16081 and assuming that the 'hangup' mechanism is due to misreading the command byte, this means that the critical time interval which can cause malfunctions is (167/800) nsec, or about 200 picoseconds.
We believe that if we were to consider using odd clock ratios such as 7:5 we might want to find out exactly where that critical time period is and make certain that we never came near it using a more complex clock division scheme. The critical time could be discovered by using two clocks with the second clock phase locked to the first so that it is synchronous but with a phase relationship that could be varied. Since we are both lazy and stupid, we will simply stick to a 2:1 ratio.
THEM ADDRESS/STATUS PINS:
In case you don't have ready access to page 11 of that spec sheet, here is the decoding of what we call address pins and what National calls status pins:
ST1 ST0 FPU function
0 0 (not used)
0 1 word transfer
1 0 reading status
1 1 sending I.D.By 'word transfer' we mean 'operation word' or 'data word'. 'Operation word' is Nat Seni terminology; we would prefer 'command word'. That's the word that tells the 16081 what to do, which implicitly contains the information about how many data words (if any) follow. The I.D. word is referred to as a 'byte' for some reason, perhaps because half the word is a 'don't care'. Since the 16032 can use other types of coprocessors, the I.D. (word or byte) tells which one to wake up and listen (or talk) closely!
Here is the sequence which must be followed to perform the simple dyadic function A = B * C, where A, B and C are all F.P. numbers located in memory:
Send the I.D. word (byte).
Send the command word.
Send the two operands, eight words total.
Wait for the 'done' signal.
Read the status word and test it for overflow.
Fetch the result, four words.Page 26, Column 1
There are a number of possible ways to write the software to perform the above series of operations. We have tested a number of them, including the use of the MOVEM.L instruction to send the two operands from the data registers, eight words, using a single instruction (it worked fine). Let us restrict ourselves to hardware considerations for the time being.
PERFORMANCE CONSIDERATIONS:
By using the 16081 as a peripheral, we must perform two memory cycles to move each operand word from memory to the 16081. In contrast, only a single memory cycle per word is needed by the 16032/16081 coprocessing system, or the Intel 8086/8087 coprocessing system. Since each uses a clock more than two times slower than the 12.5MHz 68000, but all three processors use 4 clock cycles per memory cycle, the 68000 can in fact perform those two memory cycles in slightly less time than the one cycle required by the two coprocessing systems.
We have compared the 68000/16081 peripheral system with the 16032/16081 and 8088/8087 coprocessing systems. When not performing floating point functions we would be comparing a full speed 12.5MHz 68000 with a 6MHz 16032 or a 5MHz 8086. Which would YOU rather have?
The great advantage of using the 16081 as a peripheral with the 68000 is that it permits 68000 systems to have a high performance floating point booster NOW, without the need to slow the clock rate as is true of the coprocessing systems we have mentioned.
THE SECRET SCHEMATIC:
Figure 1 is a suggested schematic of a method of connecting a 6.25MHz 16081 to a 12.5MHz 68000 with no wait states. This schematic is complete less any address or data buffers which the system will require. This schematic has been drawn for simplicity and understandability. We will first discuss the circuit as drawn, and then discuss possible simplifications.
U1 is a memory decode chip which decodes the circuitry into a unique 256 byte location in memory. A PAL is ideal for this purpose. The active low signal from the PAL is further decoded by U2A into 2 active low select signals. A memory decode with A7 low will decode the math chip and also reset U4A. A memory decode with A7 high will read the output of U3B. A high indicates that the 16081 has completed its assigned operation. The Q output of U4A was reset low, first when the I.D. byte was sent and again (redundantly) with the command word and operands (if any; operands = data words). When the operation is complete, (bar) SPC becomes an OUTPUT line for one clock cycle and, after being inverted by U2B, clocks the Q on U4A high to indicate a DONE condition. The Q output will be reset after the
Page 26, Column 2
DONE condition is detected by the 68000 and the status word is read out.
This means that it is important when writing software to wait for the DONE condition to be signaled before performing additional read or write operations with the math processor.
Because (bar) SPC is also an output, the decode from U2A passes through tri-state buffer U3A. When this buffer is not enabled, the output goes to a high impedance and is therefore equivalent to an open- collector driver. Since we had to have a tri-state buffer for the DONE line, we used the other half of the 74LS367 as the 'open collector' device.
U2B is a simple inverter used to clock U4A on the LEADING edge of the clock sent by the 16081 when it is done with an operation. Since we have half a 74LS139 left over, we use it as an inverter.
U4B is used to divide the 68000 clock by two to get a synchronous clock signal for the 16081 reasonably close to the currently rated 6MHz. For now, 16081s need a 4.2 or 4.3 volt power supply. Use a 1N5089 diode to obtain the needed voltage drop and then decouple with a ,22 ceramic and a 10 microfarad tantalum capacitor. Since U3A is a tri-state device, there should be a 1K pullup resistor connected to the 4.2 volt supply. Since future 16081s will work at the normal +5 level, leave a provision to easily install a jumper to short out the diode. The remainder of the LSTTL logic will require some bypassing too; you are expected to know this and also how to install address and data buffers if the system requires them.
As we mentioned, this schematic has been drawn for simplicity and understandability. The experienced hardware type will recognize that there are several other ways to design this simple circuit. Be sure to run the (bar) AS signal from the 68000 through two levels of delay as shown in figure 1 so that the 65 nanosecond setup time for ST0 and ST1 will be met before the chip select signal (bar) SPC goes low. The experienced hardware type will ALSO know that the address signals become valid 40 nanoseconds before the (bar) AS goes low, so we only need another 25 nsec delay. (Bar) AS and a8 should NOT be swapped because only one logic delay will not assure the needed 65 nsec total delay.
A MESSAGE FROM OUR SPONSOR:
This schematic is essentially the design of our forthcoming QD-1W board which will be offered for sale at a modest price, WITHOUT the 16081. The 16081 is not yet for sale across the counter, but we are sure the experienced hardware type will know how to sweet-talk
Page 27, Column 1
your Nat Semi type out of a sample. Hint: be sure to tell him you are going to use the 16081 with the 16032, and ask for a sample 16032 ALSO so he won't get suspicious. If you tell him you are planning to use the 16061 with the 68000 he is not likely to be very friendly (to state matters in a conservative manner).
What this means is, if your company wants to hands-on evaluate a 68000/16081 system, you can get EVERYTHING but the sample 16081 from us for less than $1000 if you have an Apple computer. It will come with sample software including source code of (some) mathematical functions on floppy disk and some other useful stuff. Even if you have to buy the Apple IIe computer, this can save you a bunch of money in engineering, technician and programmer costs. And it will give us a little profit to pay for our development work! If your bosses are stuffed shirts, we'll even toss in the design rights for the QD-1W board (but not the 68000 board) and the software rights for the munificent sum of $5, which just happens to be the price of a six-pack of Heineken Special Dark!
(We now want to address those engineering firms, not the persons who have followed our little endeavor all along.) Phone consultation is what you aren't going to get. You aren't going to believe this, but it's true. The other thing you are not going to believe is that we will not accept a purchase order. We DO accept checks. We do SEVERAL things in an unusual manner around here, such as give away design secrets like how to interface 68000s with 16081s. Some of the outfits that have finally gotten it through their thick skulls that we really DON'T accept purchase orders are Hughes Aircraft, Exxon, Chevron, Sanders Associates (those guys almost had apoplexy over the subject!) and, we almost forgot, the U.S. government. ALL of the preceding have purchased boards from us by sending a check! You probably will not understand this, but we have organized our 68000 project to give a private party (hacker) in Fargo, ND as good a deal as ANYBODY gets. We make no exceptions.
There will be additional information in future newsletters about the QD-1W when we get the board in production. And then there's issues #1 thru #24... )
MORE ADVANCED STUFF COMING!
This month we have shown how to interface the 16081 with a conventional 68000 system. Next month we will provide details on some advanced design techniques which will provide a 50% (typical) increase in floating-point throughput versus the vanilla design outlined in this issue. However, these advanced techniques require the entire system to be designed from scratch; it will not be possible to bolt these enhancements onto an existing 60000 system.
Page 27, Column 2
SOFTWARE COMING TOO!
We're going to write a transcendental package for the 68000/16081 combination. It's been a full year since we wrote the last one, published as Redlands in issue #16. Since this will be our third such package it should be easier this time around. What we are trying to do is make our 68000 boards more attractive for purchase, and to a larger audience. What do you mean, we're money-grubbing?
MEAN, UNCOOPERATIVE FNE:
Most of you will remember the tale of Professor Incredibly Intelligent, who needed information so swiftly that it had to be delivered verbally over the phone. When he failed to obtain the immediate gratification and personalized attention he felt an important personage such as himself deserved, he disdainfully went away forever. Last week we alienated a subscriber who wanted us to bring somebody ELSE up to speed from ground zero over the phone. By publishing the 16081 interfacing info we are going to get a lot of phone calls from persons who think we provide the same level of support that the persons selling $50,000 minicomputers do. Uh uh.
With the thin level of profit we have built into our price structure we simply cannot, and hence WILL not, provide the support that some folks think they are entitled to as a matter of course. When we sell a 12.5MHz 68000 and a megabyte of DRAM for $1995, there ain't no excess profit to pay for support!
Which is why we publish this newsletter. Unfortunately, lots of folks out there CANNOT or WILL NOT read. How do we solve this problem? We ignore it, and deal exclusively with folks who CAN and DO read. (Some of them can write also, and we have an overflowing file drawer to prove it!)
What will we do when we get the phone call (and we will) "we'll buy a board if only you'll answer a couple of questions?" Simple. We will instruct our secretary to hang up on the caller. If we answer their questions (i.e. provide free consulting) then they won't need to buy the board, and they won't. Is that not logical?
The fact is, those guys who cannot get by with the detailed descriptions we have provided in this newsletter need us more than we need them. The QD-1W is being designed primarily for you hackers, who have several hundred DTACK boards already. The horses' rear ends out there in those engineering firms who are going to demand free consulting can go soak their head (NOT what was originally written in this space!). We DID tell you that your FNE is not a nice person, didn't we?
Page 28
If you think a prototype 68000/16081 system which includes a one-time license fee for the 16081 interface circuitry and a one-time license fee for a 68000/16081 transcendental package including SQR, LOG, EXP, COS, TAN and ATN is worth $1250 in real money, write
DIGITAL ACOUSTICS, INC
1415 E. McFADDEN Ste F
SANTA ANA CA 92705
This "industrial 68000/16081 package" includes everything you need to evaluate and test 68000/16081 hardware AND software and to get your competition-killer into production FAST except a required Apple II or IIe and the 16081.